$ ls ~yifei/notes/
使用 partition by 查找并删除 MySQL 数据库中重复的行
Posted on:
Last modified:
在创建 MySQL 数据表的时候,经常会忘记给某个字段添加 unique 索引,但是等到想添加的时候又已经有了重复数据,这时候就需要删除重复数据。
准备数据
本文使用如下的数据作为演示:
CREATE TABLE contacts (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO contacts (first_name,last_name,email)
VALUES ("Carine ","Schmitt","carine.schmitt@verizon.net"),
("Jean","King","jean.king@me.com"),
("Peter","Ferguson","peter.ferguson@google.com"),
("Janine ","Labrune","janine.labrune@aol.com"),
("Jonas ","Bergulfsen","jonas.bergulfsen@mac.com"),
("Janine ","Labrune","janine.labrune@aol.com"),
("Susan","Nelson","susan.nelson@comcast.net"),
("Zbyszek ","Piestrzeniewicz","zbyszek.piestrzeniewicz@att.net"),
("Roland","Keitel","roland.keitel@yahoo.com"),
("Julie","Murphy","julie.murphy@yahoo.com"),
("Kwai","Lee","kwai.lee@google.com"),
("Jean","King","jean.king@me.com"),
("Susan","Nelson","susan.nelson@comcast.net"),
("Roland","Keitel","roland.keitel@yahoo.com"),
("Roland","Keitel","roland.keitel@yahoo.com");注意其中有一行重复了三次。输入完成后,数据如图所示:
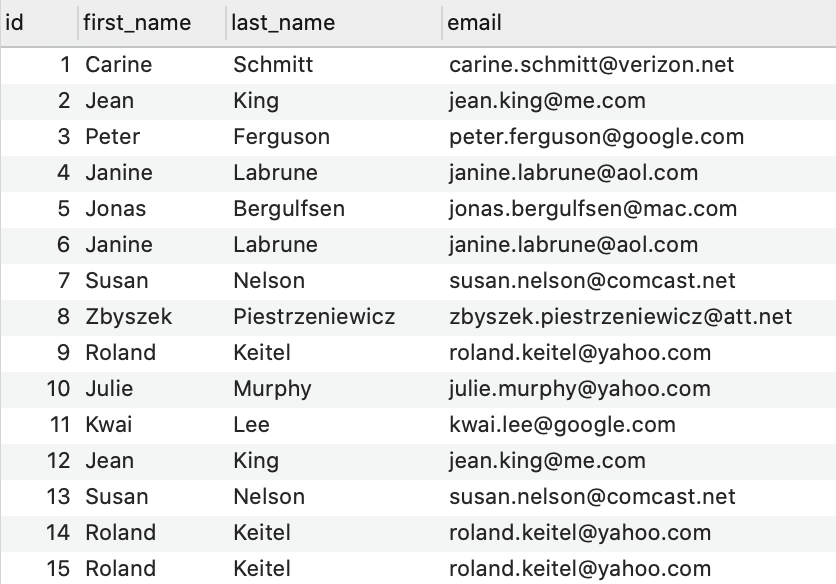
查找重复的行
使用 group by 和 having
假设我们要通过 email 字段来查找重复值。通过使用 group by 和 having 子句可以查找到哪些行是重复的。
SELECT
email,
COUNT(email)
FROM
contacts
GROUP BY email
HAVING COUNT(email) > 1;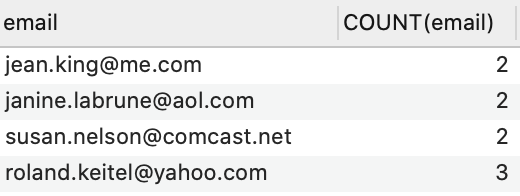
Having 就类似于 Group by 之后的 where 子句。但是这个语句还是很难解决我们的问题,我们只知道发生重复的第一行了,而不知道哪些行是重复的。这时候可以使用 partition by 语句。
使用 partition by 找出所有的重复行
需要注意的是,partition by 只有在 MySQL 8.0 之后才支持,而现在常用的是 5.6 和 5.7 版本。
Partition 语句又叫做窗口聚合语句,也就是说他会把同一个值的行聚合成一个窗口,但是和 Group by 语句不同的是,窗口内的每一个行并没有被压缩成一行,具体说 Partition by 的语法是:
window_function_name(expression)
OVER (
[partition_defintion]
[order_definition]
[frame_definition]
)删除重复的行
删除的方法有很多种,这里介绍两种。
References


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站