$ ls ~yifei/notes/
常用的反爬虫封禁手段概览
Posted on:
Last modified:
一般的网站都不欢迎爬虫流量,消耗服务器资源不说,还会把自己的商业数据爬走,于是就诞生了各种各样的反爬虫手段。
从接口的角度来说,不需登录就能访问的匿名接口一定是可以滥用的,只是破解成本的问题,而有登录状态的接口一般不容易被滥用。客户端反爬一定是可以破解的,服务端反爬往往不一定能够破解。
这篇文章有点长,没时间看的同学可以直接拉到最后看总结的思维导图。
客户端反爬
通过在访问用户本地生成一些特征来作为区分真实用户和爬虫的做法称为客户端反爬。我们知道客户端大体可以分为两类:浏览器和 APP。其中由于浏览器只能使用 JavaScript,而 JavaScript 是明文的,所以浏览器的反爬比较简单一些。而 APP 一般会把加密代码写在 C 模块中,所以破解难度比较大。
浏览器反爬
浏览器反爬的第一个手段就是“验明正身”,也就是说验证是否是浏览器发出的请求
- 验证是否是浏览器,甚至于验证是否是自动控制的浏览器
- 前端通过 JS 生成 token
对于验证是否是浏览器来说,我们可以直接使用 selenium 或者 puppeteer 这种可以程序化控制的库来爬取网站。有一些网站还会检测是不是采用了这种自动化的手段,至于如何绕过这些限制又是一个大问题了,会在后面的文章中详细阐述。
有一些 API 访问必须通过 Token,如果含有合法这个 token 就认为访问是合法的。一般来说在使用了 token 验证访问合法性的时候,服务端就不太会再对 IP 等做限制了。
Token 的计算过程往往有三个因素需要参与,分别是 key、secret 和签名算法。比如说下面的 API:
GET api.example.com/v1/search?q=XXX&type=XXX&limit=5×tamp=1501230129&app_key=424242token=XXX
其中 app_key 等于 424242,表示请求方的唯一 ID,secret 是服务器授予请求方的密码,比如 123456。而
secret = md5(sorted(["k=v" for k, v in params] + ["secret=123456"]).join("") + )也就是把所有参数都排序之后,拼接成字符串然后再计算某个 hash 值,作为 token 附在参数后面。
一般来说常用的签名算法都是这样实现的:
- 参数中加上时间戳,同时附在请求上,这样服务器可以只接受当前时间附近的真实请求,从而避免某个请求被保存下来,用作重放攻击。
- 添加参数 secret=123456 到需要计算的参数中,但是 secret 并不会出现在请求中。
- 把所有需要加密的参数都按照字典排序,然后拼接成字符串,这样是为了计算出来的值唯一。
- 计算出的 token 也附在请求上,一起发给服务器。
- 服务器根据 app_key,取出对应的 app_secret,用同样的方法计算 token,验证合法性。
app_key 的分配和含义
一般有两种理解,一种是把 app_key 作为某种类型客户端的标示,比如安卓客户端使用一个 appkey,iOS 客户端使用一个 appkey。另一种是每个用户使用一个 appkey,把 appkey 作为用户的标示。
对于网页中通过 ajax 请求 API 来说,因为 js 实际上相当于是源码公开的,所以隐藏 secret 和算法实际上是不现实的。这时候可以有两种做法,一种是把 secret 和加密算法等放到 Flash 里面去,flash 是可以编译成二进制的,所以相对来说更安全一些,不过随着 flash 的死亡,这种做法应该是逐渐淘汰了。另一种做法是 secret 动态获取,控制 secret 的来提高破解难度,同时把加密算法做一些混淆。
对于 APP 中来说,简单一点的做法可直接把 secret 和算法都直接放到代码里面,但是一般来说因为通用的加密方法大家套路基本也都那么几样,通过反编译之后加上一些基于经验的猜测很容易才出来。所以进一步可以把加密算法写到 native 层,编译成 so 文件,这样就大大提高了反编译的难度,基本可以认为是安全的。
更严厉一点的话,可以限制只有登录用户可以访问某些敏感接口,这样就完全由服务端来控制接口的访问量了,只需要注意用户注册的接口不要被滥用即可。这就是服务端的验证了,后面会继续讨论。
关于 JS 的反编译和破解也是一个很大的话题了,有机会了再写。
一个例子
比如淘宝 H5 站的接口:
当请求不带任何 cookie 时,会返回一个_m_h5_tk 和 _m_h5_tk_enc,通过下面的算法算出 sign 值再次请求
sign 算法:_m_h5_tk值的'_'前部分+时间戳+appkey+data 中间用&分隔,如下
echo -n "ddc882e0e69bb8babbfdecc479439252&1450260485494&12574478&{"platform":"8","asac":"D679AU6J95PHQT67G0B5","days":50,"cinemaid":"24053","showid":141207}"|md5sum|cut -d " " -f1服务端反爬
既然客户端的信息都是可以伪造的,那么我们干脆不相信客户端的信息了,在服务端统计一些无法伪造的信息。比如来源 IP 和登录账户信息。
通过 IP 识别用户
这种方法简单粗暴,直接根据来源 IP 来判定是否是同一个用户,如果访问过快,屏蔽请求或者需要输入验证码。但是有一个问题,好多学校或者公司都是使用为数不多的几个 IP 地址来作为出口 IP,方便管理,如果这种地方有一两个人在恶意请求,那么可能屏蔽会造成很多人访问异常。
有的大型网站甚至会对于民用 IP 和机房 IP 做出区别对待,比如 Google。
对于这种限制来说,可以放慢请求速度,或者使用多个代理 IP 来伪装自己。代理池的构建也是单独一篇文章才能讲清楚的,敬请期待。
通过验证码限制用户
不少网站往往不会直接把某个 IP 完全限制,而是在发现可疑访问时弹出验证码,这时候可以自己 OCR 识别,训练深度学习模型识别验证码(比如使用 CNN)或者直接对接打码平台。
关于不同类型的验证码和深度学习后面有时间再写。
通过 Cookies 来识别用户
上面说过直接通过 IP 来识别用户的话比较暴力,可能误伤,另一种方法就是通过 Cookie 来标示用户,如果有一个用户访问过多的话,就对这个 Cookie 做限制。
对于这种限制来说,可以直接每次请求不带 Cookie,或者预先多申请一些 Cookie,然后负载均衡一下。
除了在服务端生成 cookie 之外,网站还可以选择在客户端通过复杂的算法来生成 cookie,不过这就是客户端反爬的情况了,对于这种还是要看懂对方的 JS 还好。或者不在乎效率的话,有的时候可以直接用控制浏览器访问解决。
对于传统的静态页面的限制和破解基本上就是这些方法。不过现在很多页面都是操作丰富的动态页面,也就是我们感兴趣的消息可能是通过 ajax 加载的,我们只需要访问这个 api 就可以了。
通过登录状态
上面说的通过 cookies 来识别客户其实指的是匿名账户的 cookies。好多网站的资源都是需要登录账户来访问的,这时候首先要考虑的是能不能大批量伪造账户,可以借助于匿名邮箱和手机验证码接码平台等。
如果不能大规模的注册账户,那么还需要的是购买账户了,这个就看抓取的 ROI(投资回报比)是什么了。
最简单的情况下,网站对登录用户没有限制,那么买一个账户总是值的。
对于账户除了整体的频次控制以外,往往还会限制登录的 IP。比如说账户获得的 cookie 是和 IP 绑定的,某个 IP 每天只能登录若干个账户等等。
总结
上面的反爬和反反爬手段可以总结如下:
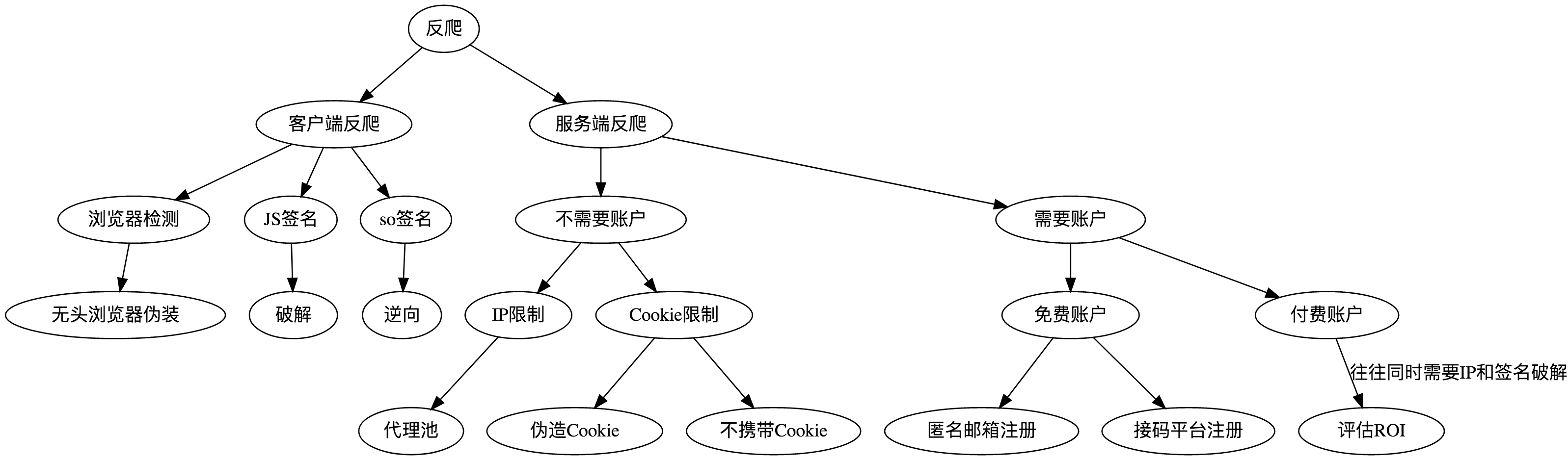
方便爬虫利用的设计缺陷
除了上述措施之外,还要避免一些设计上的缺陷被爬虫滥用。下面举几个例子。
第一个例子,自增 ID 被滥用
什么值得买的评测页面,https://test.smzdm.com/pingce/p/40205/ ,这个链接的最后一个数字就是评测的问题 ID,大小才不过几万,也就是说,我只要遍历一下这个数字,就可以把“什么值得买”这个网站的所有评测都爬取一遍,这个是在太容易被利用了。
对于这个问题,可以不要直接使用数据库的主键作为页面的 ID,而是尽量使用没有规律的数字(比如 UUID)或者至少大一点的数字作为 ID,避免被穷举遍历。
第二个例子,列表页面被滥用
链家的二手房页面,https://bj.lianjia.com/ershoufang/101102279987.html ,这个页面的 ID 就比较大了,但是我们没办法去遍历这样一个数字。这时候可以从列表页入手,https://bj.lianjia.com/ershoufang/rs/ ,只要从页面上找到所有二手房的页面地址就可以了。
第三个例子,API 的攻防
有一些 API 没有任何防护,对于这种 API 直接刷就好了,不过可能有的 API 会有根据 IP 的频次限制。
参考


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站