$ ls ~yifei/notes/
使用 cProfile 和火焰图调优 Python 程序性能
Posted on:
Last modified:
本来想坐下来写篇 2018 年的总结,仔细想想这一年发生的事情太多了,还是写篇技术文章吧。
前几天调试程序,发现 QPS 总是卡在 20 左右上不去。开始以为是 IO 问题,就多开了些并发,然并卵, 这才想到可能是 CPU 的问题。看了看监控,发现程序某一步的延迟在 400ms 左右,而且这一步是 CPU 密集的。当时开了 4 台双核的机器:(1s / 400ms) * 2 * 4 = 20 啊。看来需要优化下这一步的代码了, 那么第一步就是找到可以优化的地方。
测量程序的性能之前并没有实际做过,Google 了一番,感觉标准库的 cProfile 似乎值得一试。
要测量的代码逻辑也很简单,使用 lxml 解析 HTML,然后提取一些字段出来,这些基本都是调用的 C 库了, 解析的算法也不在 Python 中。看起来似乎没有什么能改进的地方,不管怎样,还是先跑一下吧。
cProfile 有多种调用方法,可以直接从命令行调用:
python -m cProfile -s tottime your_program.py其中的 -s 的意思是 sort。常用的 sort 类型有两个:
- tottime,指的是函数本身的运行时间,扣除了子函数的运行时间
- cumtime,指的是函数的累计运行时间,包含了子函数的运行时间
要获得对程序性能的全面理解,经常需要两个指标都看一下。
不过在这里,我们并不能直接使用命令行方式调用,因为我的代码中还需要一些比较繁重的配置加载, 如果把这部分时间算进去了,多少有些干扰,那么我们也可以直接在代码中调用 cProfile。
使用 cProfile 的代码如下:
import cProfile, pstats, io
pr = cProfile.Profile()
pr.enable()
extractor.extract(crawl_doc=doc, composition=PageComposition.row, rule=rule)
pr.disable()
s = io.StringIO()
sortby = "cumtime" # 仅适用于 3.6, 3.7 把这里改成常量了
ps = pstats.Stats(pr, stream=s).sort_stats(sortby)
ps.print_stats()
print(s.getvalue())把需要 profile 的代码放到 pr.enable 和 pr.disable 中间就好了。注意这里我们使用了 cumtime 排序,也就是累计运行时间。
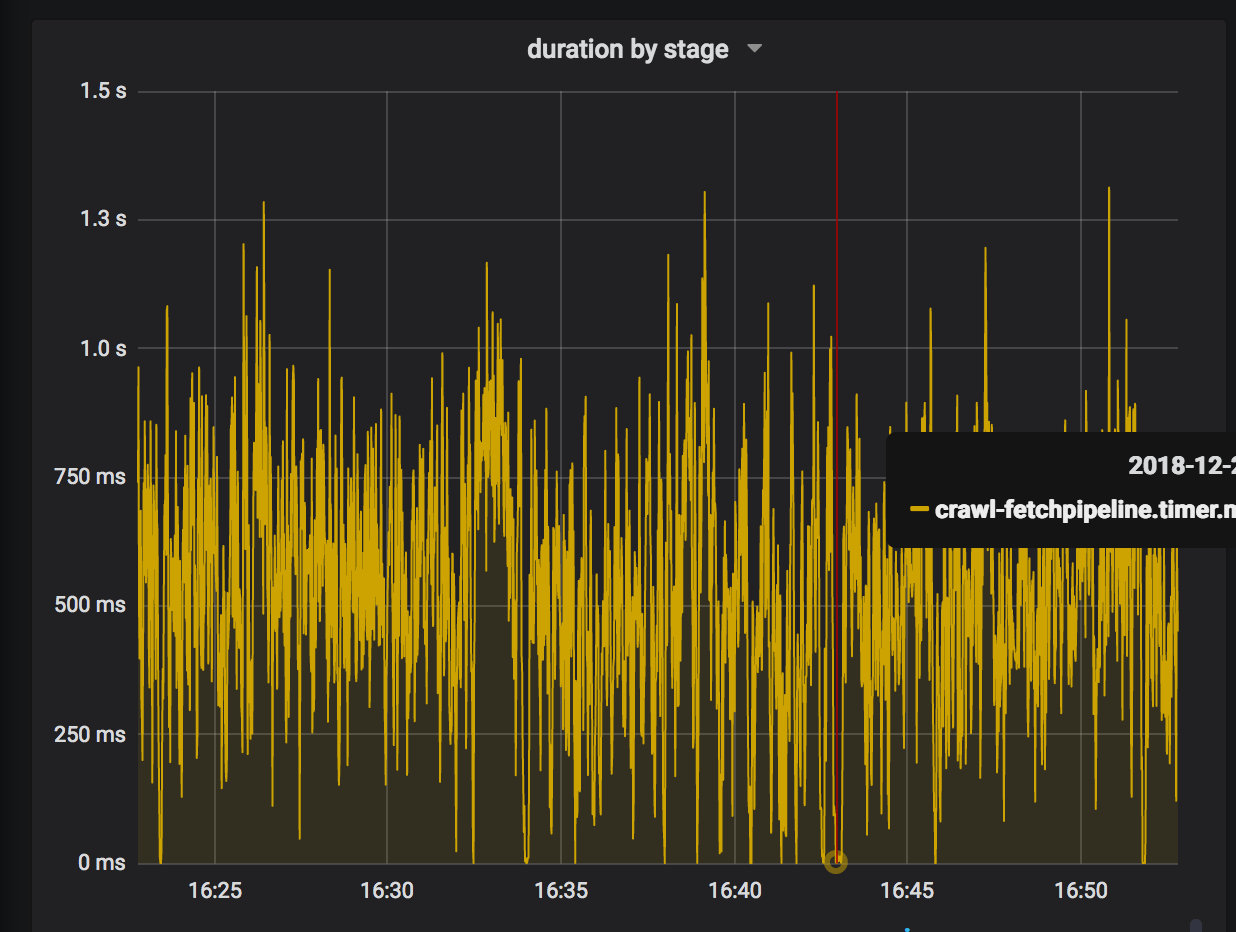
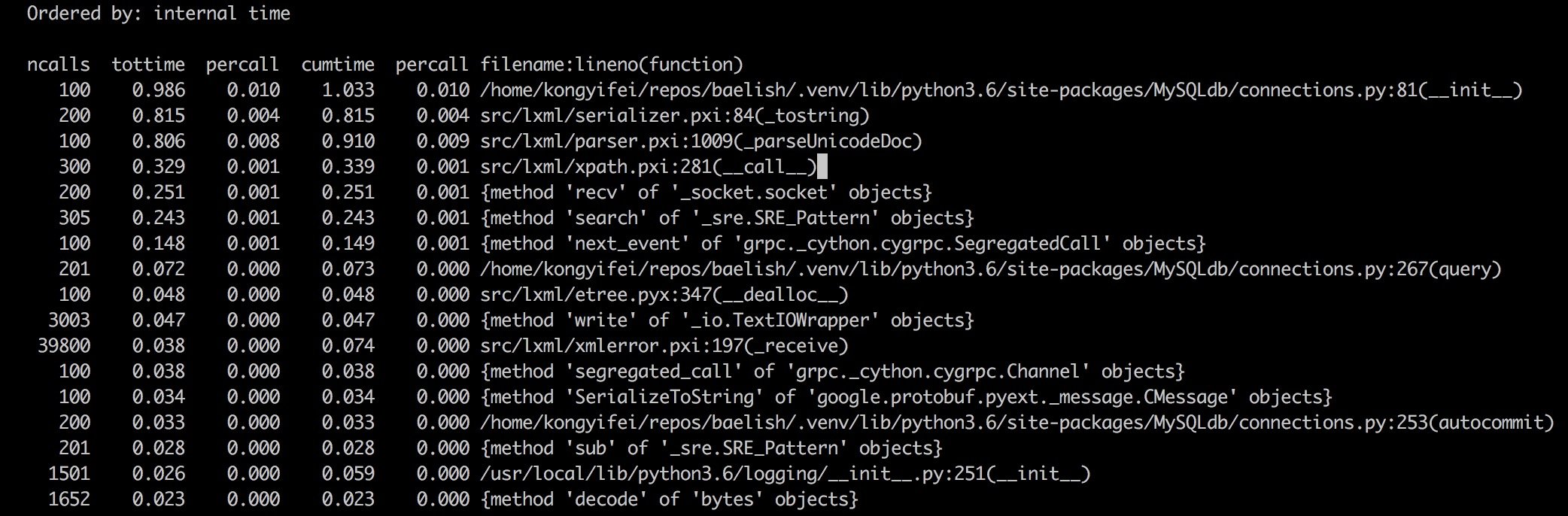
结果如下:
我们可以看到总的运行时间是 200ms,而其中红框内的部分就占了 100ms! 如果能够优化调的话,性能
一下子就能提高一倍。红框内的代码是做什么的呢?我们知道解析一个 html 文档,第一步是建立 DOM 树,
通常情况下,我们可能会从其中抽取一些链接。在网页中,链接不一定是绝对路径,也可能是
/images/2018-12-31-xxx.jpg 这样的相对路径。lxml 库帮我们做了一个贴心的默认值,那就是在构造
DOM 树的时候,根据传入的 url 来吧页面中的所有 url 都重写成绝对路径。看起来这是个很贴心的功能,
但是在这里却成了性能瓶颈。为什么很耗时呢?大概是因为需要遍历整个 DOM 树,重写所有的链接吧。
这显然不是我们需要的,我们只需要把抽取之后的链接还原成绝对路径就好了,而不是事先把所有链接都
重写一遍。所以在这里我们直接去掉这个功能就好了。
修改代码之后,再次运行 profile 脚本,时长变成了 100ms:

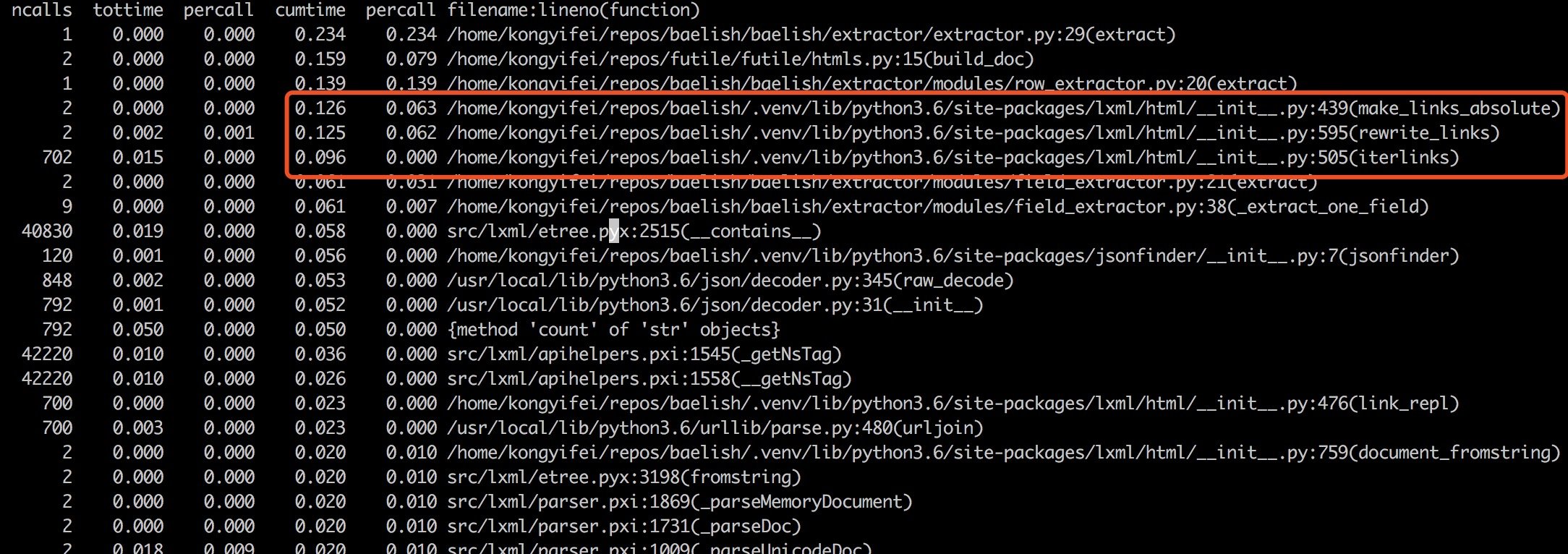
这时候我们接着看,程序中下一个比较大头的时间占用:jsonfinder 和 json decode/encode。
jsonfinder 是一个有意思的库,它自动从 HTML 中查找 json 字符串并尝试解析,但是有时候也不太准。 经常为了找到特定的值,还是需要使用正则。那么对于这个可有可无的功能,性能有这么差,还是删掉好了。
通过删代码,现在性能已经是原来的四倍了。
这时候发现代码里面有正则还挺花费时间的,不过还好,暂时先不管了。
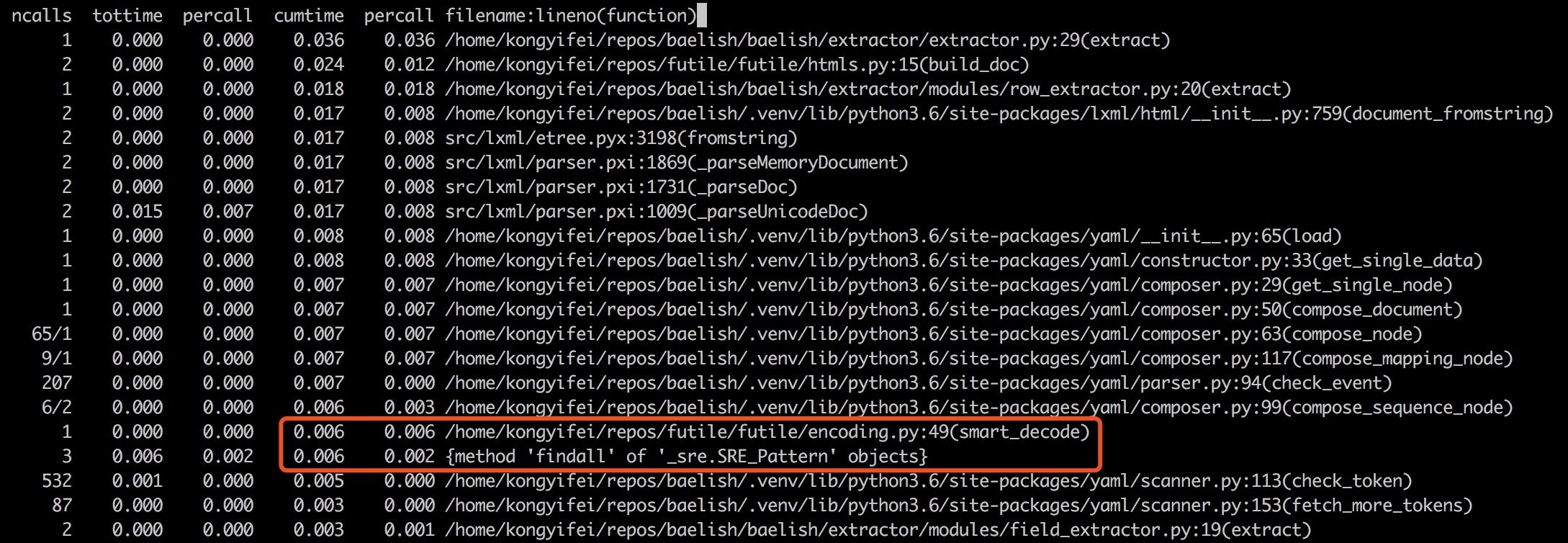
刚刚都是只运行了一遍,测量结果难免有随机性,必定有失偏颇,实际上应该使用多个测试用例, 成千上万次的跑,才能得到一个比较准确地结果。
上面这个小步骤基本没有什么可以优化的了,下面我们把优化目标扩大一点,并把次数先定为100.
下面这种图是按照 tottime 来排序的:
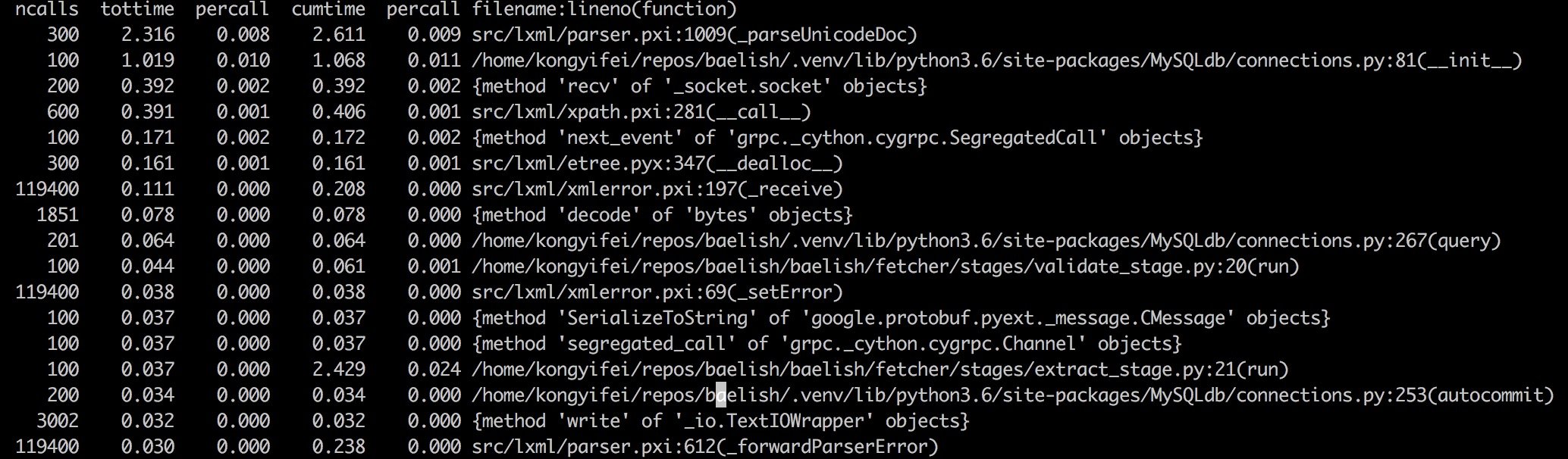
注意其中最耗时的步骤是 parseUnicodeDoc,也就是建树了,这是符合预期的,然而旁边的 ncalls 一栏却不太对劲了。我们明明只运行了 100 次,为什么这个函数调用了 300 次呢?显然代码中有 重复建树的地方,也就是有隐藏的 bug。这种地方不经过 profile 很难浮现出来,因为程序本身的 逻辑是对的,只是比较耗时而已。
优化之后,终于变成了 100. 从 cProfile 的表格现在已经看不出什么结果来了,下一步我们开始 使用火焰图,可视化往往能让我们更容易注视到性能瓶颈。(为什么不一开始就用火焰图呢?因为 我以为很麻烦。。实际很简单)
Python 中有一个第三方包(见参考文献)可以直接从 cProfile 的结果生成火焰图:
- 在原有的代码中加上一句:
pr.dump_stats("pipeline.prof") - 调用该工具:
flameprof pipeline.prof > pipeline.svg
然后打开 SVG 文件就可以了:
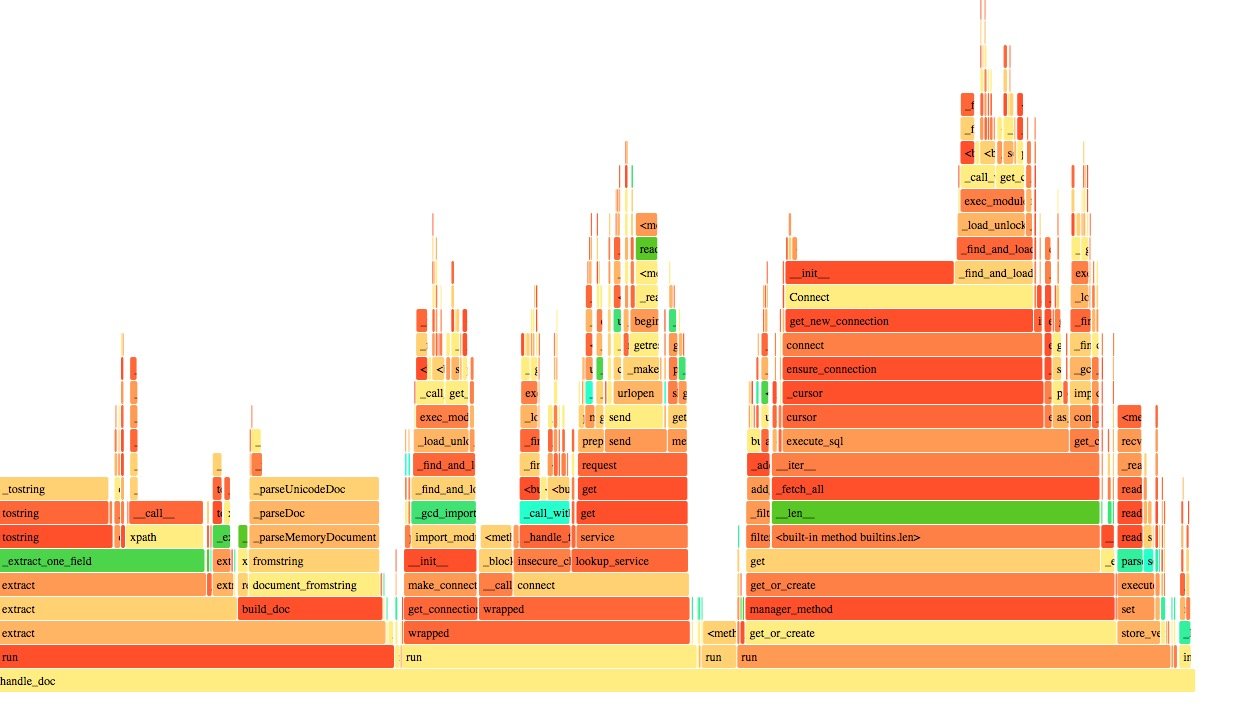
其中火焰的宽度代表了运行的时长,我们现在的优化目标就是这些耗时比较长的步骤。
可以看大其中 mysql 的访问占了绝对的大头,按理说跑100次的话,不应该每次都花费时间在建立
连接上啊,这里一定有问题。经过排查发现在某处链接是使用了 close_old_connections 来保证
不会抛出数据库断开的异常,这还是在头条带来的习惯。。close_old_connections 的功能是关闭
已经失效的链接,看来我的理解还是有误的。先把这块删掉,最终解决应该是这块放到一个队列里,
统一存入数据库。
去掉之后:
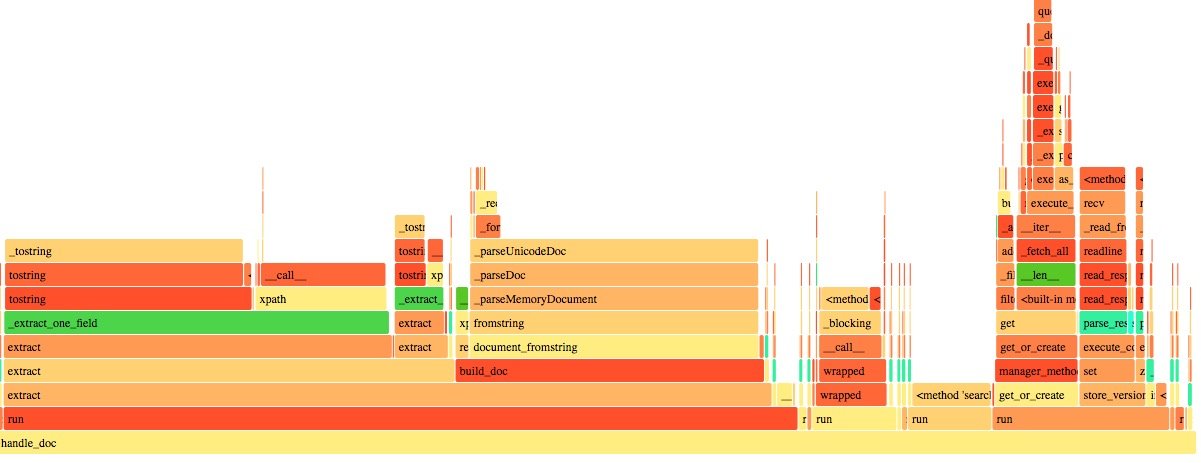
现在的大头又变成 lxml 的,又动了优化它的心思,lxml 是 libxml2 的一个 Python binding, 查了下应该是最快的 html parser 了,这块真的没有什么优化空间。盯了一会儿,眼睛最终看到了 一个小角落:
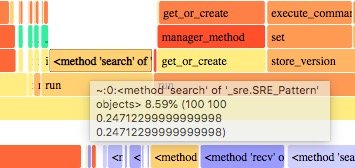
一个正则匹配居然占用了 8% 的运行时间,太不像话了。老早之前就听说 Python 的标准库正则性能 不行,现在才发现原来是真的挺差劲的。Python 标准库的 re 模块采用的是 PCRE 的处理方式,而 采用 NFA 的处理方式的正则要快很多,这块还需要再看一下。不过眼下倒是可以直接换一个库来解决。 regex 模块是 re 模块的一个 drop-in replacement.
pip install regex and import regex as re,就搞定了
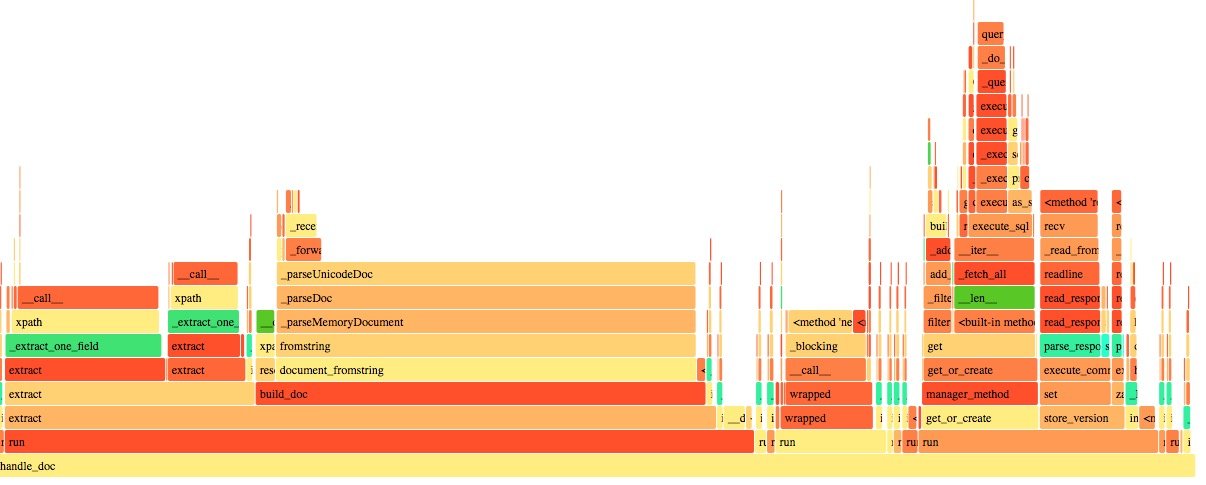
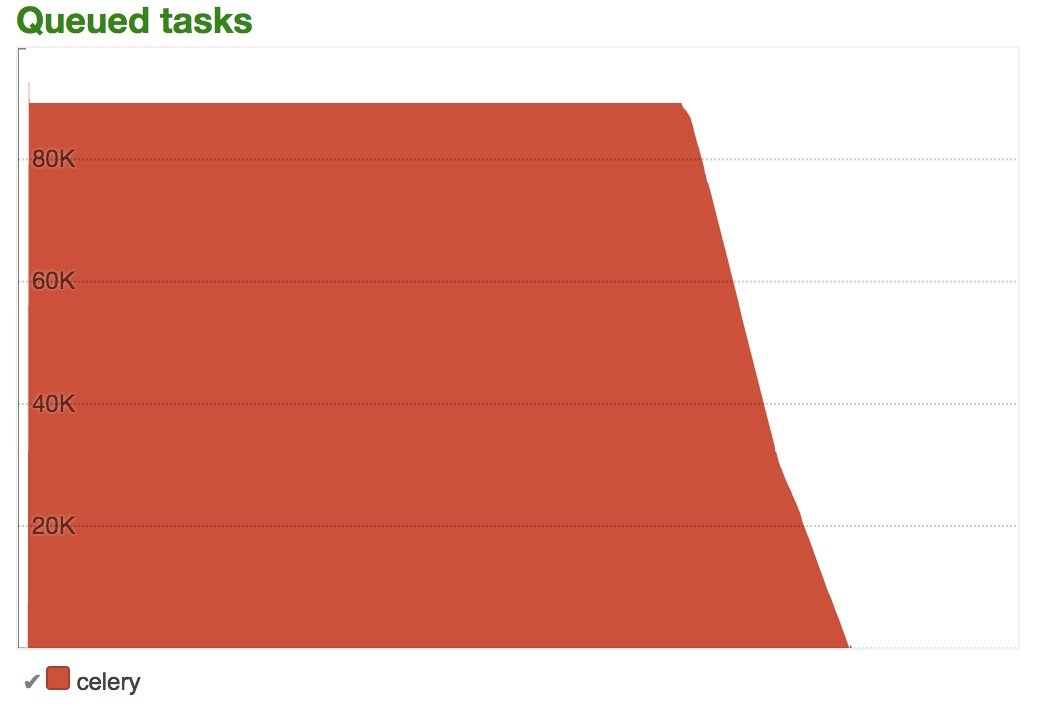
可以看到正则那块直接消失了。提升还是很大的。时间不早了,当天的优化就到此结束了。上线之后, 积压一下子就下去了:
后记
要想调试的时候方便,在写代码的时候就要注意,尽量使自己的代码 mock-friendly 一点。如果需要 引入外部的数据库、服务、API等等各种资源,最好有一个开关或者选项能够不加载外部资源,或者 至少能够很方便地 mock 这些外部服务,这样方便对每一个小单元进行 profile。
总有人吐槽 Python 的性能低下,但是 Python 本来就不是做计算任务的呀,Python 是一门胶水语言, 是用来写业务逻辑的,而不是用来写CPU密集的算法的。事实上复杂的解析一般都会用 C++ 这种硬核 语言来写了,比如 numpy TensorFlow lxml。大多数程序员一天 90% 的工作除了和产品经理撕逼以外, 也就是在写 CRUD,也就是调用这些包。所以瓶颈一般在 IO 上而不在 CPU 上,而解决 IO 的瓶颈手段 就多了,Python 中至少有 多进程、多线程、AsyncIO、Gevent 等多种方法。不过方法多其实也是一个 弊端,这几种方法可以说是基本互不兼容,对各种第三方库的支持也参差不齐。而 Go 在这方面就做地 很好了,语言直接内置了 go 关键字,甚至都不支持多线程。所有的库都是支持一个统一的并发模型, 对于使用者来说更简单。
Zen of Python 中有一句:There should be one way -- preferably only one way -- to do a thing. 这点上 Python 本身没有做到,反倒是 Go 实践地非常好。
扯远了,程序的瓶颈其实不外乎CPU、内存和 IO 三个方面,而 cProfile 和火焰图是判断 CPU 瓶颈的 一把利器。
后面还发现了一些性能瓶颈,也列在这里:
yaml 的反序列化时间过长。解决方法是添加了一个 Expiring LRU Cache,不要每次都去加载,当然 牺牲的是一点点内存,以及当规则变更时会有一些延迟,不过都是可以接受的。之前早就听人说 Thrift 的序列化性能相比 Protobuf 太低,现在想想序列化和反序列化还真是一个很常见的性能瓶颈啊。
存储使用了 360 的 pika,pika 可以理解为一个基于 rocksdb 的硬盘版 redis。最开始的时候没多想, 随便找了台机器搭了起开,把上面的问题解决之后,pika 的延迟很快大了起来,机器的监控也显示 IO 基本被打满了。这时候才发现原来这台机器没有用 SSD,果断换了 SSD 问题基本解决了。如果再有问题 可能就需要集群了。
性能这个问题其实是典型的木桶理论的场景,系统的整体性能是由最差的一块决定的。所以也是一个不断 迭代的过程。
祝大家新年快乐~
参考文献


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站