$ ls ~yifei/notes/
蛤?什么是 raft 协议?
Posted on:
Last modified:
Raft 协议是一个分布式的一致性协议,主要通过 Leader Election 和 Log Replication 两个步骤 来实现高可用的一致性状态存储。
这篇文章并不是 Raft 协议的一个完整介绍,只是其中核心概念的一个总结概括,要完全理解所有细节还是得看论文。
Leader 选举
- 每个节点有三种状态:follower、candidate、leader。
- 作为 leader 有任期 (term) 的概念,根据基本法必须选举上台。Term 是一个自增的数字。
- 作为 leader 要不断发送心跳给 follower,告诉他们一律不得经商。
- 所有节点都有一个随机的定时器(150ms~300ms),当 follower 没有收到日志后就会升级为 candidate,term + 1,给自己投一票,并且发送 Request Vote RPC 给所有节点,也就是 apply for professor 啦。
- 节点收到 Request Vote 后,如果自己还没有投票,而且比自己在的任期大,那就说明水平比自己 高到不知道哪里去了,就投票出去,否则拒绝。
- 如果节点发现自己的票超过了一半,就吟两句诗,钦点自己是 leader 了
- 新的 leader 上台后,继续发送日志昭告天下,其他的 candidate 自动灰溜溜的变为 follower 了
日志复制(Log Replication)
- 所有的请求都发送给 leader,一律由中央负责。
- leader 把收到的请求首先添加到自己的日志当中
- 然后发送 Append Entries RPC 给所有的 follower,要求他们也添加这条日志
- 当大多数的节点都添加这条日志之后,leader 上这条日志就变为了 committed
- leader 再发送给所有的节点,告诉他们这条日志 committed
- leader 返回给客户端,告诉他请求成功
分区容忍
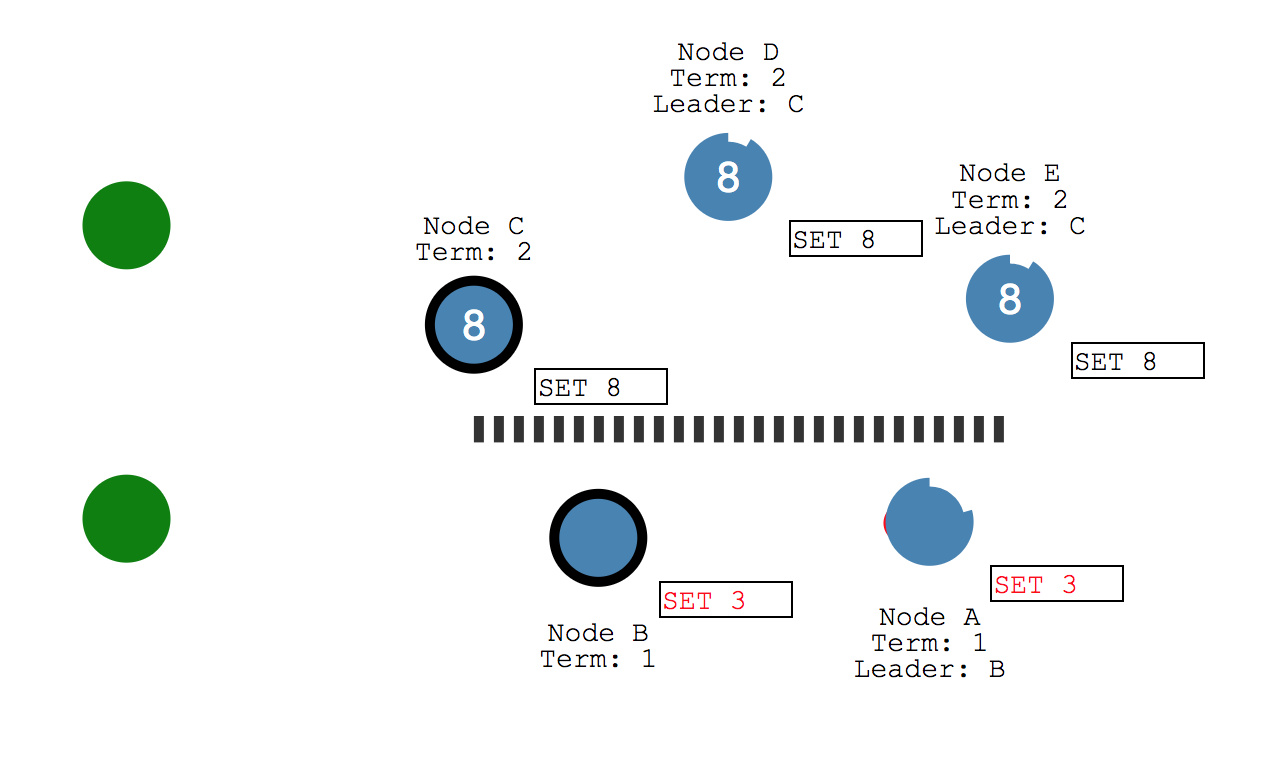
如果网络发生了分区,也就是另立中央了,那么 raft 的日志复制机制也可以保证一致性。
比如下图中,由于中间的网络分区,出现了两个 leader,这之后如果给下面的 leader(Node B)中 发送请求,因为它向一个节点中同步日志,所以只能获得两个节点的确认,因此提交失败。而如果向 上面的 leader 中发送请求,可以向两个节点中同步日志,也就是说一共三个节点都是同步的,那么 就提交成功。不会出现两个 leader 分叉的情况。
参考资料:


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站