$ ls ~yifei/notes/
图解一致性哈希
Posted on:
Last modified:
起源
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object) % N一切都运行正常,再考虑如下的两种情况;
- 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache
m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射
公式变成了
hash(object) % (N-1); - 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了
hash(object) % (N+1);
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难, 洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是 consistent hashing...
一致性哈希
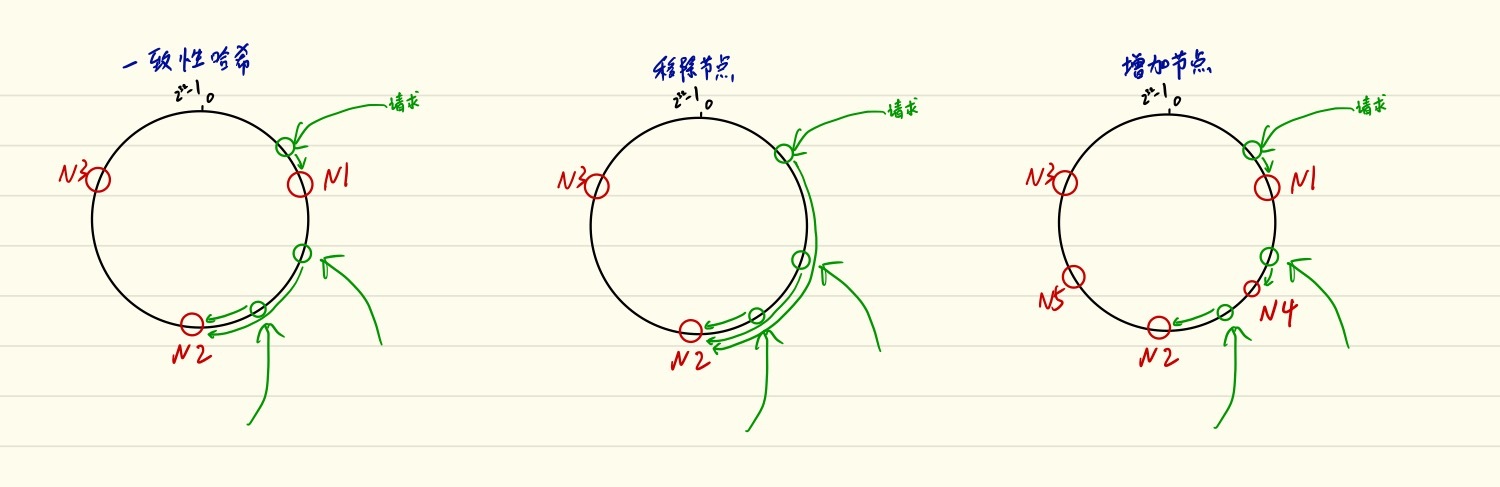
一致性哈希把哈希值想象成一个环,比如说在 0 ~ 2^32-1 这个范围内,然后将节点(名字、IP 等) 求哈希之后分不到环上。当有访问请求时,把请求信息求哈希之后,寻找小于该哈希值的下一个节点。
当有节点宕机的时候,请求会依次查找下一个节点,从而不让所有节点的缓存都失效。
当加入新节点的时候,只会影响一个区间内的请求,也不会影响其他区间。
如下图所示:
虚拟节点
以上虽然解决了大部分问题,但是还有三个问题:
- 节点有可能在分布不均匀。
- 当一个节点因为负载过重宕机以后,所有请求会落到下一台主机,这样就有可能使下一台主机也 宕机,这就是雪崩问题。
- 不同主机处理能力不同如何配置不同的量。
这时候可以引入虚拟节点。原始的一致性哈希中,每个节点通过哈希之后在环上占有一个位置,可以 通过对每个节点多次计算哈希来获得过个虚拟节点。
比如说,本来我们通过节点的 IP 来计算哈希
hash("10.1.1.1") => n1
hash("10.1.1.2") => n2
hash("10.1.1.3") => n3现在引入两倍的虚拟节点之后
hash("10.1.1.1-1") => n1-1
hash("10.1.1.1-2") => n1-2
hash("10.1.1.2-1") => n2-1
hash("10.1.1.2-2") => n2-2
hash("10.1.1.3-1") => n3-1
hash("10.1.1.3-2") => n3-2如图所示
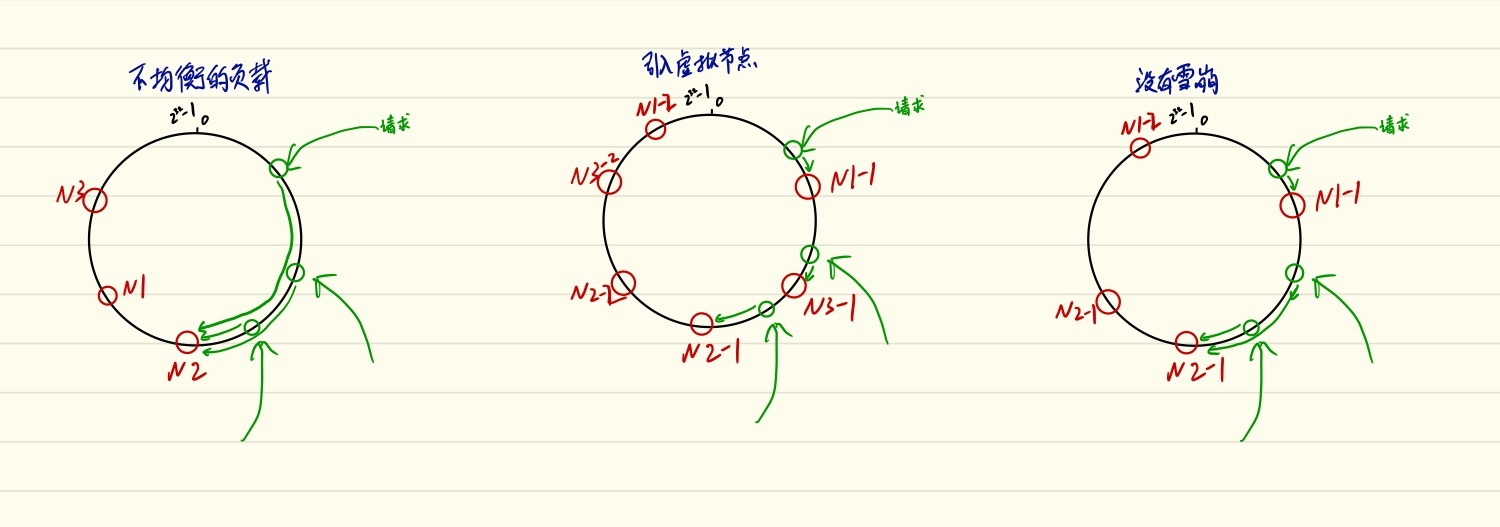
引入虚拟节点之后:
- 平衡性得到了直接改善
- 主机是交替出现的,所以当一个节点宕机后,所有流量会随机分配给剩余节点
- 可以给处理能力强的节点配置更多地虚拟节点。
最后,一致性哈希可以用跳表或者平衡二叉树来实现
参考文档


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站