$ ls ~yifei/notes/
跳表(skiplist)
Posted on:
Last modified:
平衡二叉树可以实现 O(logn) 的查找复杂度。跳表可以实现相当于平衡二叉树的复杂度查询数据,而代码实现比较简单。在 Redis 中,zset 就用到了 skiplist。
跳表是用并连的链表来实现的查询结构
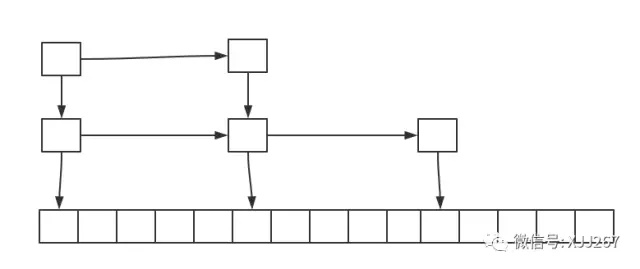
- 每个节点包含的指针的层数是由一个随机数决定的。
- 跳表的时间复杂度和平衡二叉树相同,但是在实现上要简单很多。
- 跳表是有序的,跳跃表的特点就是有序的,所以对于一些有序类型的数据,比如整数,日期这种,用跳跃表可以进行范围查找。
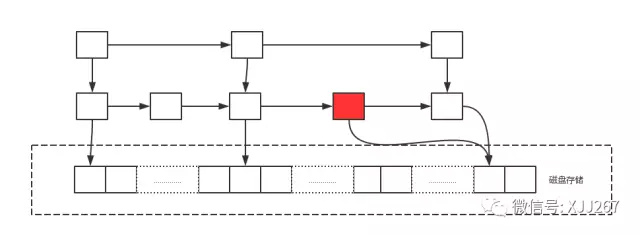
- 在构建跳跃表和查询跳跃的复杂度一致,所以也比较适合于在线的实时索引查询,可以来一个文档,一边查找就一边知道要如何进行插入操作了。
- 保存到磁盘和从磁盘载入也比较简单,因为本质上是几个链表,所以保存的时候可以按照数组的方式分别保存几个数组就可以了。
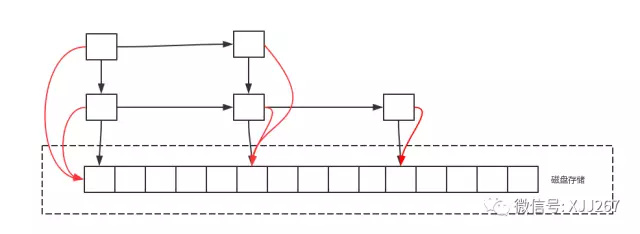
一些优化
空间优化,把底层的表放到硬盘里,影响增加删除节点的效率
时间优化,用数组代替链表,可以使用二分查找而非遍历
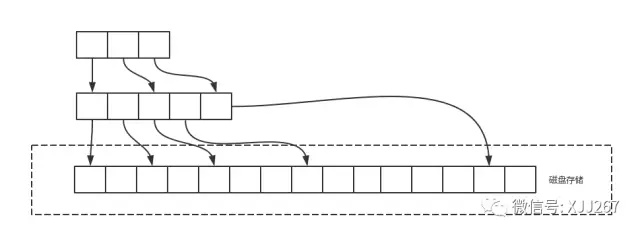
对于类似时间这种数据,比如 24 小时对应 1440 分钟对应 86400 秒钟
甚至可以固定直接用索引随机访问
实现
https://github.com/begeekmyfriend/skiplist/blob/master/skiplist.h
参考


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站