$ ls ~yifei/notes/
读《The Anatomy of a large-scale hypertextual Web search engine》
Posted on:
Last modified:
Google 在 1997 年的论文 [1], 到现在 (2017) 的话,已经有二十年的历史了,然而对于编写一个 小的搜索引擎,依然有好多具有指导意义的地方。
The Anatomy of a large-scale hypertextual Web search engine 这篇论文应该是一片总结性质的 论文,而且论文并没有多少的关于数据结构等的实现细节。只是大体描绘了一下架构。
Google 的算法
首先,Google 大量使用了在超文本也就是网页中存在的结构,也就是锚文本和链接。还有就是如何 有效的处理在网页上,所有人都可以任意发布任何文字的问题,Google 在这片文章里给的解决方案是 PageRank.
在 20 年前,主要问题是,网页已经开始快速增长,然而当时的所有搜索引擎给出的结果只是搜索 结果的数量也增长了,却没能把最相关的结果放在首页。因为人们并不会因为给出结果多而去多看几页, 所以这样的结果是不可取的。在设计 Google 的过程中,Google 还考虑了随着 web 规模的增长,会对 现有的体系造成的影响以及如何应对。
Google 还表达了对当时的搜索引擎都是商业化的,因而一些诸如用户查询之类的结果无法共学术应用的 情况表达了不满。(呵呵,Google 这不是打自己的脸么)
对于 PageRank 算法,提到了简单的公式:
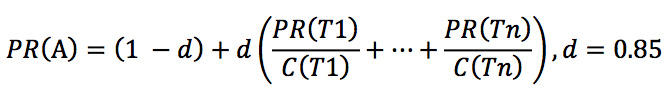
其中 Tx 表示的是指向 A 页面的所有页面,C 表示的是一个页面上所有的外链。对于这个公式的解释 是这样的。假设有一个随机的浏览者,他不断的点击网页中的链接,从不点后退,直到他感到烦了, 然后在随机的拿一个网页开始点击。其中 d 就表示了这个人会感到烦了的概率。这样造成的结果就是 如果一个网页有很多的的外链指向他的话,他就有很大的机会获得比较高的 PR, 或者如果一个很权威的 站点指向的他的话,也有很大机会获得比较高的 PR.
对于锚文本,大多数网站都是把他和所在的页联系起来,Google 还把锚文本以及 PR 值和它指向的页面联系起来。
Google 的架构
其实这部分才是我最感兴趣的地方。之所以今天会抽出时间来阅读这篇论文,主要就是想写个小爬虫,然后发现写来写去,太不优雅了,才想起翻出 Google 的论文读一读。
Google 整体架构
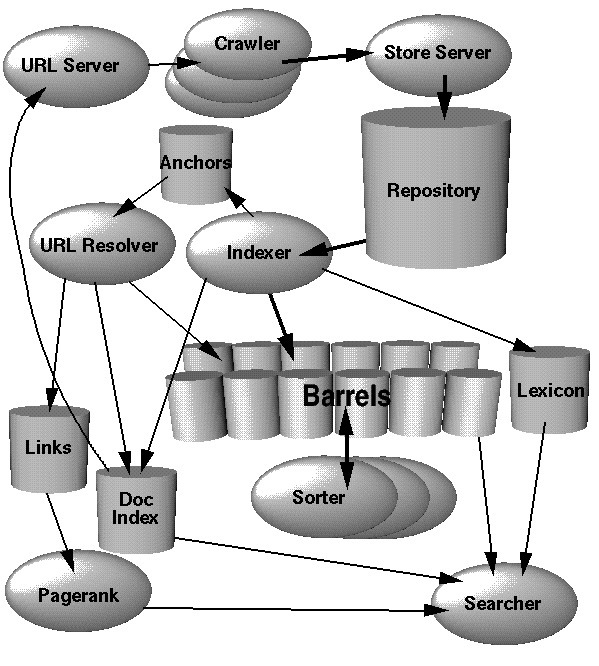
Google 的架构非常的模块化,基本上可以看到整个图,就知道每个模块是负责做什么的。大概分成了几个部分:爬虫(下载器), indexer, barrel, sorter, 和 (searcher) 前端服务。
其中
- 爬虫负责下载网页,其中每一个 url 都会有一个唯一的 docID.
- indexer 负责解析网页中的单词,生成 hit 记录,并产生前向索引。然后抽出所有的链接。
- URLResolver 会把 indexer 生成的锚文本读取并放到锚文本和链接放到索引中,然后生成一个 docID -> docID 的映射数据库。这个数据库用来计算 PageRank.
- sorter 根据 indexer 生成的正向索引,根据 wordID 建立反向索引。为了节省内存,这块是 inplace 做的。并且产生了 wordID 的列表和偏移
- searcher 负责接收用户的请求,然后使用 DumpLexicon 产生的 lexicon 和倒排和 PageRank 一起做出响应。
用到的数据结构
由于一个磁盘寻道就会花费 10ms 的时间 (1997), 所以 Google 几乎所有的数据结构都是存在大文件中的。他们实现了基于固定宽度 ISAM, 按照 docID 排序的 document 索引,索引中包含了当前文件状态,指向 repository 的指针,文件的校验和,不同的统计信息等。变长信息,比如标题和 url 存在另一个文件中。(YN: SSD 对这个问题有什么影响呢)
hitlist 指的是某个单词在谋篇文档中出现的位置,字体,大小写等信息。Google 手写了一个 htilist 的编码模式,对于每个 hit 花费 2byte
barrel 中存放按照 docID 排序存放 document
模块
爬虫
爬虫又分为了两个部分,URLServer 负责分发 URL 给 Crawler. Crawler 是分布式的,有多个实例,负责下载网页。每获得一个 URL 的时候,都会生成一个 docID. Google 使用了一个 URLServer 和 3 个 Crawler. 每一个 Crawler 大概会维持 300 个连接,可以达到每秒钟爬取 100 个网页。并且使用了异步 IO 来管理事件。
DNS
Google 指出爬虫的一个瓶颈在于每个请求都需要去请求 DNS. 所以他们在每一个 Crawler 上都设置了 DNS 缓存。
YN: 对于 HTTP 1.1 来说,默认连接都是 keep-alive 的,对于 URLServer 分发连接应该应该同一个域名尽量分发到同一个 crawler 上,这样可以尽量避免建立连接的开销。
indexer 会把下载到的网页分解成 hit 记录,每一个 hit 记录了单词,在文档中的位置,和大概的字体大小和是否是大写等因素。indexer 还会把所有的链接都抽取出来,并存到一个 anchor 文件中。这个文件保存了链接的指向和锚文本等元素。
rank
Google 并没有手工为每一个因素指定多少权重,而是设计了一套反馈系统来帮助我们调节参数。
结果评估
Google 认为他们的搜索能够产生最好的结果的原因是因为使用了 PageRank. Google 在 9 天内下载了 2600 万的网页,indexer 的处理能力在 54qps, 其中
拓展
query cacheing, smart disk allocation, subindices
链接合适应该重新抓取,何时应该抓取新连接
使用了 NFS, 性能有问题
YN:
如何判定为一个 hub 也 -> 识别列表 hub 页的链接产出率 -> 根据一个列表页是否产生新连接来动态的调整 hub 页的抓取频率


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站