$ ls ~yifei/notes/
爬虫利器 Chrome Headless 和 Puppeteer 最佳实践
Posted on:
Last modified:
翻译自:https://docs.browserless.io/blog/2018/06/04/puppeteer-best-practices.html
在做爬虫的时候,总会遇到一些动态网页,他们的内容是 Ajax 加载甚至是加密的。虽然说对于一些大站来说,分析接口是值得的,但是对于众多的小网站来说,一个一个分析接口太繁琐了,这时候直接使用浏览器渲染就简单得多了。
爬虫难免要爬一些动态网页,使用诸如 Qtwebkit 或者 phantomjs 之类的渲染工具总有无法渲染的问题,最好的方法直接使用 Google Chrome 渲染网页。前一段时间 Google Chrome 支持了 headless 模式,也就是可以在没有显卡,没有显示器的服务器上原生运行,更令人惊喜的是还提供了一个 node 的库来操作。这个库叫做 puppeteer, 顾名思义,操作木偶的人,哈哈,挺有创意的名字。
以往比较流行的是 selenium + phantomjs 的组合,不过在自从 Google 官方推出了谷歌浏览器的无头模式和 puppeteer 这个库以后,稳定性和易用度都大幅得到了提升,本文也主要探讨谷歌浏览器和 puppeteer。另外 puppeteer 也有第三方的 Python 移植,叫做 pyppeteer,不过这个库目前来看不太稳定(个人使用体验)。另外 pyppeteer 这个库使用了 asyncio,如果你的爬虫使用的是普通的同步语法,那么也还是不方便调用 pyppeteer 这个库,个人建议还是使用官方的 node 版 puppeteer,如果需要在 Python 中调用,直接调用 node 然后渲染就可以了。
browserless 是一家在提供云端浏览器渲染服务的公司,本文翻译了他们关于如何提升无头浏览器稳定性和性能的两篇文章并添加了本人在使用过程中遇到的一些问题和经验总结。browserless 的两篇原文链接在最后。 browserless 已经运行了 200 万次的 chrome headless 请求,下面是他们总结出来的最佳实践:
一、不要使用无头浏览器
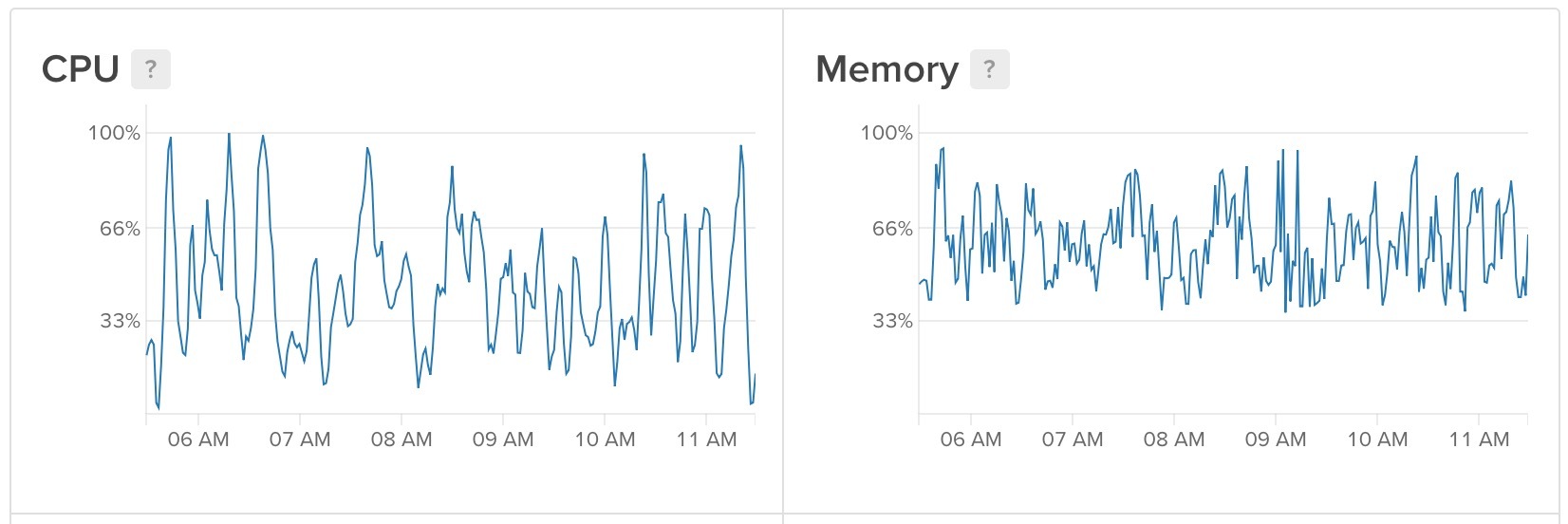
无头 Chrome 占用的大量资源
无论如何,只要可以的话,不要运行无头浏览器。特别是千万别在你跑其他应用的服务器上跑。无头浏览器的行为难以预测,对资源占用非常多,就像是 Rick and Morty 里面的 Meseeks(美国动画片《瑞克和莫蒂》中,召唤出了过多的 Meseeks 导致出了大问题)。几乎所有你想通过浏览器用的事情(比如说运行 JavaScript)都可以使用简单的 Linux 工具来实现。Cheerio 和其他的库提供了优雅的 Node API 来实现 HTTP 请求和采集等需求。
比如,你可以像这样获取一个页面并抽取内容:
import cheerio from "cheerio";
import fetch from "node-fetch";
async function getPrice(url) {
const res = await fetch(url);
const html = await res.test();
const $ = cheerio.load(html);
return $("buy-now.price").text();
}
getPrice("https://my-cool-website.com/");显然这肯定不能覆盖所有的方面,如果你正在读这篇文章的话,你可能需要一个无头浏览器,所以接着看吧。
二、不要在不需要的时候运行无头浏览器
我们遇到过好多客户尝试在不使用的时候也保持浏览器开着,这样他们就总能够直接连上浏览器。尽管这样能够有效地加快连接速度,但是最终会在几个小时内变糟。很大程度上是因为浏览器总会尝试缓存并且慢慢地吃掉内存。只要你不是在活跃地使用浏览器,就关掉它。
import puppeteer from "puppeteer";
async function run() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://www.example.com/");
// More stuff ...page.click() page.type()
browser.close(); // <- Always do this!
}在 browserless,我们会给每个会话设置一个定时器,而且在 WebSocket 链接关闭的时候关闭浏览器。但是如果你使用自己独立的浏览器的话,记得一定要关闭浏览器,否则你很可能在半夜还要陷入恶心的调试中。
三、 page.evaluate 是你的好朋友
Puppeteer 有一些很酷的语法糖,比如可以保存 DOM 选择器等等东西到 Node 运行时中。尽管这很方便,但是当有脚本在变换 DOM 节点的时候很可能坑你一把。尽管看起来有一些 hacky,但是最好还是在浏览器中运行浏览器这边的工作。也就是说使用 page.evaluate 来操作。
比如,不要使用下面这种方法(使用了三个 async 动作):
const $anchor = await page.$("a.buy-now");
const link = await $anchor.getProperty("href");
await $anchor.click();
return link;这样做,使用了一个 async 动作:
await page.evaluate(() => {
const $anchor = document.querySelector("a.buy-now");
const text = $anchor.href;
$anchor.click();
});另外的好处是这样做是可移植的:也就是说你可以在浏览器中运行这个代码来测试下是不是需要重写你的 node 代码。当然,能用调试器调试的时候还是用调试器来缩短开发时间。
最重要的规则就是数一下你使用的 await 的数量,如果超过 1 了,那么说明你最好把代码写在 page.evaluate 中。原因在于,所有的 async 函数都必须在 Node 和 浏览器直接传来传去,也就是需要不停地 json 序列化和反序列化。尽管这些解析成本也不是很高(有 WebSocket 支持),但是总还是要花费时间的。
四、并行化浏览器,而不是页面
上面我们已经说过尽量不要使用浏览器,而且只在需要的时候才打开浏览器,下面的这条最佳实践是——在一个浏览器中只使用一个会话。尽管通过页面来并行化可能会给你省下一些时间,如果一个页面崩溃了,可能会把整个浏览器都带翻车。而且,每个页面都不能保证是完全干净的(cookies 和存储可能会互相渗透)。
不要这样:
import puppeteer from "puppeteer";
// Launch one browser and capture the promise
const launch = puppeteer.launch();
const runJob = async (url) {
// Re-use the browser here
const browser = await launch;
const page = await browser.newPage();
await page.goto(url);
const title = await page.title();
browser.close();
return title;
};要这样:
import puppeteer from "puppeteer";
const runJob = async (url) {
// Launch a clean browser for every "job"
const browser = puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const title = await page.title();
browser.close();
return title;
};每一个新的浏览器实例都会得到一个干净的 --user-data-dir (除非你手工设定)。也就是说会是一个完全新的会话。如果 Chrome 崩溃了,也不会把其他的会话一起干掉。
五、队列和限制并发
browserless 的一个核心功能是无缝限制并行和使用队列。也就是说消费程序可以直接使用 puppeteer.connect 而不需要自己实现一个队列。这避免了大量的问题,大部分是太多的 Chrome 实例杀掉了你的应用的可用资源。
最好也最简单的方法是使用 browserless 提供的镜像:
# Pull in Puppeteer@1.4.0 support
$ docker pull browserless/chrome:release-puppeteer-1.4.0
$ docker run -e "MAX_CONCURRENT_SESSIONS=10" browserless/chrome:release-puppeteer-1.4.0上面限制了并发连接数到 10,还可以使用MAX_QUEUE_LENGTH来配置队列的长度。总体来说,每 1GB 内存可以并行运行 10 个请求。CPU 有时候会占用过多,但是总的来说瓶颈还是在内存上。
六、不要忘记 page.waitForNavigation
如果点击了链接之后,需要使用 page.waitForNavigation 来等待页面加载。
下面这个不行
await page.goto("https://example.com");
await page.click("a");
const title = await page.title();
console.log(title);这个可以
await page.goto("https://example.com");
page.click("a");
await page.waitForNavigation();
const title = await page.title();
console.log(title);七、使用 docker 来管理 Chrome
Chrome 除了浏览之外,还会有好多的莫名其妙的线程,所以最好使用 docker 来管理
docker run -p 8080:3000 --restart always -d --name browserless browserless/chrome
const puppeteer = require('puppeteer');
// 从 puppeteer.launch() 改成如下
const browser = await puppeteer.connect({ browserWSEndpoint: 'ws://localhost:3000' });
const page = await browser.newPage();
await page.goto('http://www.example.com/');
const screenshot = await page.screenshot();
await browser.disconnect();</pre>启动的时候指定 --user-data-dir
Chrome 最好的一点就是它支持你指定一个用户的数据文件夹。通过指定用户数据文件夹,每次打开的时候都可以使用上次的缓存。这样可以大大加快网站的访问速度。
const browser = await pp.launch({
args: ["--user-data-dir=/var/data/session-xxx"]
})
不过需要注意的是,这样的话会保存上次访问时候的 cookie,这个不一定是你想要的效果。


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站