$ ls ~yifei/notes/
Baelish: An Retrospection
Posted on:
Last modified:
Baelish 是一个基于配置的爬虫系统,用现在时髦的话来说叫做 Low Code 爬虫系统,它的目标是让 标注员也能够通过可视化界面的来抓取数据。最近一年一直都在写这个项目。在这个过程中可以是说 踩了无数的坑,杀死了不少脑细胞终于搞了一个勉强能用的 demo 版本。
完全自己一个人做了一个系统,在这个过程中有不少的收获和教训,趁还没有忘记赶快记下来。这篇 文章主要是总结下在其中犯得各种错误,以备查阅。
这篇文章断断续续也补充了一年,也算是对我一年半创业经历的一个经验总结吧。
为什么
为什么要做一个低代码爬虫呢?首先来回答下这个问题了吧,下图应该不言而喻了:
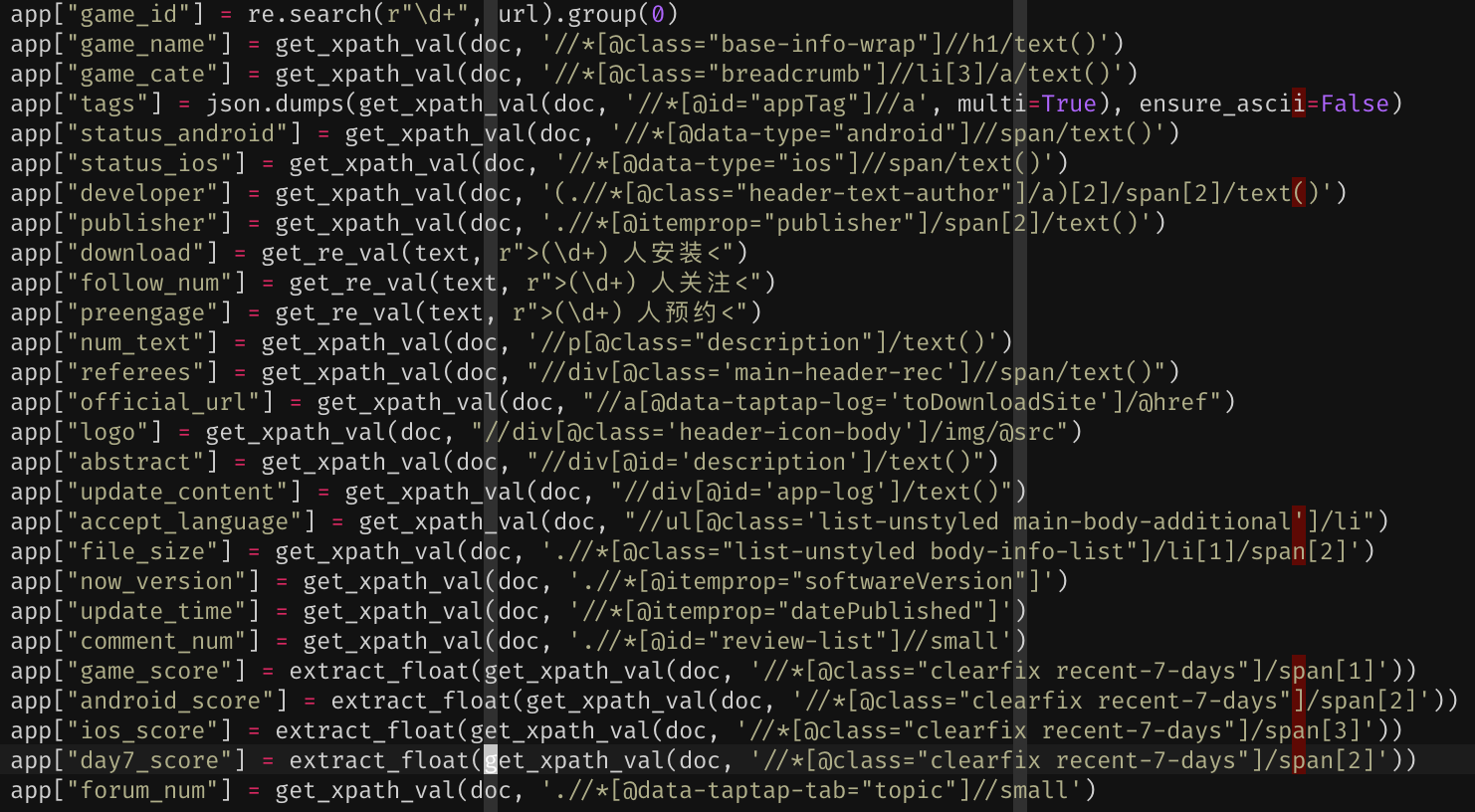
这些代码很容易出错,而且都是重复代码,自然想到了把代码改成配置。
过早优化
开始设想的服务太大了,想做一个超牛逼的大而全的东西。所以在一开始的时候就拆成了好多的 repo, 每个模块都拆成了不同的微服务,中间使用 RPC 调用,并且每次打成好多不同的镜像,部署的时候也 很麻烦。其实这里的问题在于不明白其中的逻辑,而是生搬硬套架构,犹如东施效颦。
分库是一个很大的问题,最开始的时候总是想着把库拆出来做一个基础组建库,然后拆出来了好多库, 甚至把代理和抽取都单独出库来,实际上没有必要保持代码的纯洁性,这是我常犯的一个错误。这方面 造成了镜像打包都很麻烦,而且要在各种库之间切来切去,依赖也要重复安装好多次。当某一个组件 需要被其他人复用的时候再拆出来也不迟,像是 npm 那样拆得太散也不好。
最开始把项目分成了若干个代码仓库。baelish 负责调度和下载,jaqen 负责代理管理,bolton 负责
解析和存储,inf 是基础库的代码,futile 是和爬虫业务无关的 utility,app_common 是数据库的
orm 和 Django 的后台,conf 是配置文件、idl 是 protobuf 代码。对于一个小型项目来说,分这么
多库显然太复杂了。最终干掉了大多数库,只保留了 baelish、app_common、idl、conf 和 futile 库,
现在准备再干掉其他的库,只留下 baelish 和 futile。并且在打包 docker 镜像的时候全部都打包
成一个镜像,这样部署也方便些。
即使在拆成不同仓库比较好的时候,也没必要打成好多的镜像,如果一个人维护多个镜像的话,很容易 就会忘记每个镜像的每个版本到底更新了什么。
另一个问题就是典型的“过早优化”。早期我把很多只是保存状态,做增删改查的部分都抽象成了单独的
服务,实际上封装到一个接口中,读取 redis 就很好,在做好监控的前提下等到 redis 扛不住的
再优化也不迟。实际上在项目的早期,做一个单体应用就很好,需要抽出来的地方抽出来,能不抽出
来尽量不抽出来。这里的问题其实还是在于没有理解逻辑,生搬硬套架构。看过了一千篇文章,却
还是做不好一个架构。
强行使用刚学会的技术
总体思想上出的问题,老是想把知道的工具都用上去,试试好不好玩儿,而不是从项目需要的角度来选择。这种思想其实早就知道是错的,但自己第一次负责一个项目的选型和架构的时候还是忍不住手痒痒。不过好在自己老早就知道这样是错的,至少以后再做项目不会犯这种错误啦。
这点主要体现在 Frontier 和后来的 Scheduler 上面。在定向爬虫上,Frontier 本身就不是必须的,根本没必要多此一举。Scheduler 也没有必要使用 token bucket 算法,使用堆是最好的。token bucket 或者 leaky bucket 还是必须的。这里也考虑过多,单点部署其实就够了。单 master 多 slave 虽然看起来会有单点故障,但是确实是最简单高效的模式。
基础组件选型
选型上出的问题主要在于消息队列,日志服务和容器平台。监控上的选型倒是正确的。监控的选型完全是错误的,Prometheus 才是唯一正解。这里的问题还是在于东拼西凑概念,没有完整的理论体系。
实际上这里的根本问题还是在于东拼西凑架构,而不是有一个统一的设计理念。总体来看,主要原因就在于两个:
- 知识不足,确实需要学习
- 选型过于小众,坑太多
其实核心还是没有自己的逻辑,东拼西凑。这一点在读完 Facebook 员工的一篇文章后有了极大改善。
容器编排平台
ansible -> nomad -> k8s
最开始想通过 ansible 直接部署到多台机器上,然后使用 consul 服务发现的机制。但是这个过程中发现在同一个机器上如果部署同一个服务的多个副本的话不是很方便。但是爬虫需要扩展的时候,需要在一台机器上部署多个实例,这时候就需要容器的编排平台了,另外就是日志也需要收集。
脑袋一热,开始寻找一个真正的编排平台。
首先考虑了 Kubernetes,但是还是觉得太复杂了,概念有点多,感觉用不然,然后就凭借着对 hashicorp 的信任选择了 nomad,结果证明又是一个大坑。
去年 (2018) 的十一假期研究了几天 k8s,概念是在太多了,看得我实在是头昏脑涨,所以中途放弃了 k8s。这时候因为已经选用了 consul,就注意到了同一家公司出的 nomad。nomad 号称是一个轻量级的调度平台,只有一个 binary,而且还能够和 consul 无缝集成。nomad 简直是一场灾难。首先他的调度是有问题的,尤其是其中一个比较有特色的功能叫做 parameterized job,顾名思义就是可以以不同的参数启动一个任务。这个任务就总是启动失败,nomad 的日志收集也有问题,还有看不到日志的情况。由于 nomad 的社区较小,在 GitHub 上只有不到一万的 stars,所以出了问题以后只能看到几个悬而未决的 issue,然后就是干瞪眼。nomad 的编排经常无法看到运行中的容器,迷之找不到 container, 没有好的解决方案。
最终还是上了 Kubernetes,其实过了入门的坎,再看 k8s 还是很简单的。另外一点就是 k8s 通过 cluster IP 这个功能很好地解决了服务发现的问题,完全不用再去手工注册服务,代码量节省了不少,也省去了维护 consul 的工作。选择了使用阿里云托管版的 k8s,虽然贵了点,但是对于公司来说,这点钱确实不算什么了。这时候距离我学习 k8s 的概念也有了几个月了,经过几个月的沉淀,一些难点也逐渐想明白了。使用了 k8s 之后,确实没有什么大的问题了。
这里要特别说明一下 k8s 上的服务发现实现的优点。在传统的集群中,比如说我们使用 zk 或者 consul 作为服务发现的话,一种模式是服务方主动把自己的 IP 和端口注册到注册中心,在退出的时候解注册。这样的不好是侵入性比较强,在客户端中需要自己去解析服务地址。k8s 上的服务注册在 etcd 中,然后内部服务访问的时候通过 DNS 解析的方式获取到 IP。那么这里就有个问题了,一般语言或者系统的实现中,DNS 可能有也可能没有缓存,那么当服务在集群中漂移的时候怎么能保证总能访问到正确的地址呢?k8s 的实现比较神奇,他的 clusterIP 是虚拟的,并且在服务的整个生命周期都是不变的,也就是说,DNS 和 IP 一定是固定的,服务层有没有 DNS 缓存就无所谓了。
消息队列
redis -> rabbitmq -> redis stream -> celery -> kafka
最开始混淆了缓存和队列的区别,对于爬虫的不同任务来说,需要分别放在不同的缓存,而不是直接放到同一个队列,这样是无法调度的。这里在于对于消息队列的理解不够深入。
最开始的时候觉得 kafka 实在太重了,虽然很熟悉 kafka 的使用,但是考虑到自己运维的压力,所以就想找个轻量级的工具。首先尝试使用了 Redis,但是因为消息都堆在内存里面,一旦消费端发生了阻塞,很快就 oom 了。
后来尝试了使用更加“工业级”一点的 rabbitmq,毕竟还自带了管理界面。但是折腾了一周,rabbitmq 总是会神奇的自动退出,查了下可能是 Erlang VM 的问题,并且没有更多任何日志消息,最终放弃了。而且 rabbitmq 没有一个很好的 python 客户端,有一个叫做 pika 的 python 客户端,但是基本跟玩具一样,抽象层级不够,仅仅提供了非常原始的包装,什么也没有,完全需要自己写。关于 rabbitmq 不稳定的问题,可以参见 Hacker News 上的 讨论, 在 rabbitmq 上至少坑了半个月。
在之后,正好 redis 发布了 5.0 版本,提供了 redis stream 的功能,号称是和 Kafka 一样的设计理念,因为我本身对 kafka 的概念比较熟悉,而且 redis 本身也是比较稳定的,所以就尝试了一下。但是还是感觉被坑的不浅。当时 redis stream 刚刚出来,Python 的客户端还没有支持这个特性,导致一些代码还需要自己解析响应,在这上面画的时间不少不说,做出来的还不太稳定。redis stream 虽然是借鉴了 kafka 的概念,但是还是有很多地方不同的,而且有一些东西也没有明确,这就导致实现起来各种小 bug 满天飞。还有一个就是 ack 的语义不明,导致消费总是重复,最终放弃了。最重要的一点是,redis 想实现 kafka 这个 API 本质上就是南辕北辙了,kafka 之所以可以做到 consumer group 能够重放这个功能,就是因为在硬盘上有比较好的消息堆积能力,而 redis 作为一个内存数据库,注定做不到好的消息堆积能力。实际上单纯模仿 kafka 的 API 是没有意义的。这里还是没搞明白消息队列和缓存的关系。
因为 ack 的问题总解决不好,又想使用一些比较全家桶的方案,这时候 celery 进入了我的视野。celery 作为一个异步框架,只需要编写 worker 函数就行了,至于 broker 可以使用 rabbitmq 或者是 redis。因为 rabbitmq 之前一直跑不起来,所以选择了 redis。用了大概一个月的时间还是比较满意的。celery 虽然可以支持 redis,但是他是使用了 kombu 这个库,把 redis 封装成了 AMQP 协议,也就是 rabbitmq 来使用的,这就导致了想要改一些东西的话还是很复杂的。
celery 提供的并发模型太少,只有 prefork 和 gevent 勉强可以用,然而 gevent 又回导致严重的内存泄漏问题,而爬虫是需要大量的并发请求的,在这种情况下,celery 就成了一个瓶颈。另外一个问题是对于失败任务的 retry 机制在 celery 中也很不明确,celery 本身封装了不少层,导致捕获出异常来成了一个很大的问题,而我们又不能设置永久重试,最终结果就是有一些任务在重试到最大次数之后被永久丢弃了。这里也是和爬虫这个业务紧密相关的,毕竟下载的失败率是很高的。同时 redis 毕竟还是在内存里的数据库,一开始提到的 OOM 的问题还是没有彻底解决,这时候就想着在换一下了。
终于又想起了 Kafka,开始的时候,实际上还是觉得 kafka 太难搭建了,用起来的话太浪费时间了。但是实际上最开始可能用 redis 就可以,等到性能出问题了再去换到 kafka 上。使用 kafka 的话,上面两个问题都可以得到解决,自己编写客户端可以任意选择并发模型,而且对于抓取失败的链接可以自定义重试策略。
仔细把 Kafka 的文档通读了一遍,然后又看了下官方的例子,发现运行一个简单的 kafka 集群其实并没有想象的那么难。kafka 背后的公司现在叫做 confluent,他们官方提供了 kafka-docker 的镜像,最终使用 docker-compose 把 kafka 和 zk 都做了一个单节点的部署,虽然听起来可用性不高,但是到目前为止确实没有发生过任何问题,当然以后流量大了肯定要搞集群的,不过这也不过就是需要把 compose 文件改几个参数罢了。至于 kafka 的客户端,则是使用 confluent-kakfa 加 threadpoolexecutor 自己封装了一个。
日志服务
阿里云 SLS -> 坑
当部署多个实例的时候,实际上日志的收集是非常关键的一步,可以说必须在横向扩展之前完成,而之前忽略了这一点。在 debug 的过程中,日志非常重要,日志的缺失也就拖累了开发进度。
另外,阿里云的日志服务也是一个大坑,连基本的全文搜索都做不到,搞一些花里胡哨的东西也不知道有啥卵用。plain old grep 才是排查问题的利器啊。现在看来可能还是需要 loki + kafka 来做一下。
关于业务性日志和程序性日志的区别,会单独再写文章讨论。
RPC 选型和微服务
Thrift -> gRPC -> http+json
在 RPC 框架的选择上,主要纠结在 thrfit 和 gRPC 之间,虽然花了一些时间学习和比较两个框架,但是最终感觉还是值得的。不过也还是使用地太早了,在最开始的时候完全没有使用 RPC 的必要性。
在前东家的时候一直用 thrift,但是 thrift 不支持 uint64,这点让我一直不是很爽。而且听说 thrift 的序列化性能和 protobuf 相比差了不少。于是乎,在研究了一段时间 thrift 和 gRPC 的优缺点之后,毅然选择了 gRPC。
但是问题来了,gRPC 虽好,暂时用不上啊。虽然设想着代理、解析、下载等等可能都需要微服务,但是最终都没有用,因为运维几个微服务的代价太高了,人手不够的时候还是单体应用好,不能切分太细了。而且其实在最开始并没有多大的流量,不如先使用快糙猛的 http 服务搞起来。另外 gRPC 的 Python 版本到目前为止还不支持多进程模式,所以更要慎重使用。
除了 gRPC 以外,还使用 protobuf 定义了几个全局透传的对象,后来也移除了。开始想着是这几个对象可能最终要被持久化存储,那么使用 protobuf 做序列化再适合不过了。对于应用的内部通信,实际上用语言本身的对象就是最好的了,protobuf 完全没必要,画蛇添足。周围同事普遍不会用也是一个因素。
监控系统
influxdb -> influxdb + telegraf -> influxdb -> 坑
不懂的地方很多,虽然最终也没弄对,但是收获也很大。大概花了一个月的时间首先学习了什么是时序数据,然后系统调研了 opentsdb、influxdb、prometheus 等等时序数据库或者监控方案的优缺点,最终选择了 influxdb + grafana 的方法。这里有个坑就是对于带有各种 tag 的数据的聚合方式,各家都支持地不太好,哪怕是 influxdb 的亲儿子 telegraf 也会把数据理解错,这里只能是自己根据业务来实现了一个打点的库,自己在客户端做好聚合工作。
因为其中被 telegraf 坑了一把,所以监控这块还有一些短板,不过补上也很简单,只是工作量的问题。
监控使用了 influxdb 现在看来是一个比较正确的选择,但是没能及早发现 statsd 还是走了一些弯路,不过学习了下时序数据库的相关东西也算没有浪费时间吧。
influxdb 和 statsd 实际上是两个大坑。influxdb 好多关于时序性数据的特点和要求没有在文档中提及,需要自己试错才知道。而 statsd 基本完全没考虑标签,导致聚合结果完全是错的。
现在看来还是要用 prometheus 比较好一点。
业务逻辑
从业务逻辑上来说,也有不少可以优化的地方。
规则变动
从我自身而言,对于整个业务逻辑的梳理不是很明确,排期预计也不准确。最终导致的结果就是,爬虫要执行的规则变来变去,导致做了好多次返工。比如抽取的规则,最开始定义了页面的字段,最后才统一到必须是行的字段上。最开始觉得直接写 yaml 就可以了,最终还是回到做了一个 GUI 上。
调度
由于在开始项目之前,刚刚看了 MIT 的信息检索导论这本书,其中提到了爬虫的 frontier 组件,然后就模仿着写了一个调度的组件,可是根本就是想多了。书中提到的调度算法是面向的全网爬取,也就是说搜索引擎级别的爬取,实际上和我要解决的半定向爬取的问题不是一个问题。虽然浪费了大概一个月时间实现了这么一个东西,但是实际上并没有什么卵用,最后抛弃了。
调度中一个很重要的问题就是频控。我是知道一个叫做 token_bucket 的算法的,在这里就特别想把这个算法用上,但是事实有一次证明我错了。对于这种主动发起请求,自己能控制频率的情形,最好的方法还是 sleep 就好了。
可是毕竟 sleep 总让人感觉可能会很低效啊,这时候我又想起了操作系统中进程调度的各种优先级算法。如你所知,又掉进了坑里。这里的调度问题实际上和进程调度完全不是一个问题,非要用那个优先级算法实际上除了会造成好多任务没有在运行以外,并没有什么卵用。
最终采用的方式就是每个线程负责 N 个爬虫的调度,简单轮询,稳定又高效。
下载解析
这里可以说是整个项目从一开始设计基本正确的地方了。使用 pipeline 的模式,把每个步骤都抽象成一个 stage,其实和 django 的 middleware 有点像,最终完成一个网页的抓取。
这里唯一的坑就是开始想把规则加载、代理和解析都设计成一个 RPC 服务去调用,后来发现完全没有精力搞这些事情,就算了。
缓存
设计地太复杂了。考虑了缓存加载和缓存过期两种时间,搞得大家都比较迷惑。最终发现绝大多数的项目也都不需要缓存,这块直接去掉了。
代理
本来想自己使用阿里云或者 adsl 机器自己搭个集群,但是自己搭建的 IP 对于当前的场景来说不够用啊,而且自己搭建太复杂了,还是直接买得好。
存储系统
对于 MySQL 竟然了解地不是很充分。高性能 MySQL 这本书当时也才只看了 50%。当时我竟然以为事务可以让一批数据批量入库,想想真是 naive 啊。
数据库的选择和使用上其实暴露了我对于 MySQL 性能的无知了。最开始没有考虑到连接数问题,导致 MySQL 被锁死。之后又没有如何批量插入的问题,导致数据插入的丢失问题也很严重。当然这个问题也不完全是我的个人问题,把半结构化的数据存入 MySQL 本来就是一个比较奇葩的选择。
管理
以下讨论对事儿不对人,总体感觉就是一群聪明人在做傻事儿。
高层眼光较短
创业公司的管理果然是有非常大的问题。CXO 们除了 F 有做通用爬虫的想法之外,其他人还停留在线性增长的思路上,只是关心短线结果,不考虑长远的规划。这对于爬虫的开发也产生了一些不良影响。实际上,作为科技公司,不论是否直接参与代码的编写,对于其中的好奇心和敬畏感是都要有的,如果只是关心结果,很难做到高效。话说回来,你对技术都没有好奇心,在科技领域混有毛线意思啊。
CEO 最大的问题在于在公司呆的时间太短,对于公司发生的事情掌控力太差,频繁见客户不一定有用,耐心打磨产品才是正途。
总结下来,高层的问题在于:
- 心不齐,没有得到足够的授权来做爬虫平台这个事情。好多方案不一定哪个更好,但是必须定下来一个,好多无意义的争论是没有意思的。
- 真带不动,kafka 不知道,grpc 也不知道,metrics 也不知道。根源还是上一个问题,人心不齐,这种问题竟然还需要说服他们,谁不会就赶紧学就好了。
没有长远规划
作为一家依赖爬虫数据的公司,在爬虫系统的规划和建设上毫无调研和思路。而当我提出建设爬虫平台的时候,除了 CEO 竟然没人能理解其中的意义。在公司的开始阶段,当然要小步快跑,迅速满足业务需求为主。但是当进展到一定程度之后,可维护程度应该是一个更重要的指标。
没有统一架构
公司一共四个负责爬虫的,竟然有两套框架。没有人说了算,没有统一的框架使得代码不能复用,也不能被其他人维护。这让我想起了头条强推 TCE 的场景,所有业务不管适不适合一律上云,这样大家每个人想到的功能点才能改进之后惠及每一个人,毕竟“刀越磨越快”。
很简单的东西,没有人能明白我的思路,反复说了,大家还是按照低效的方法来做,实际上最终还是要返工。比如说对于监控问题,很明显很清晰的一个问题,利用现有工具也可以做得很好,非要自己写一通,最后的结果也是很差的。对于缓存的问题,有很成熟的思路可以直接使用,竟然理解不了,也抽象不到这个层级,最终竟然重抽问题还是没有解决。
另外,过于倚重阿里云和其他第三方服务,缺乏自研和探索精神。实际上诸如灵犀和 jumpserver 之类的服务是非常难用的,而开源的工具可以做到很好,把时间花在这些 trivial 的东西上最终产出也不是很好。阿里云的日志服务,k8s 服务,es 服务等等都不是非常地好用,甚至可以说非常难用了。而整体研发的思路,F 的思路则是能用阿里云尽量用阿里云,没有一点探索精神。
战略的迷失
盲目追求数据的大而全,但是又不能保证数据质量,没有做精做细某一块。举个例子来说:
- 电商数据。最基础的抓取问题没有解决,或者说这个数据根本就是不可能获得的,阿里的风控团队是吃素的吗?更何况其中还有法律风险问题。
- 招投标数据。这里面可以做的点非常非常多。而且作为一手的数据来源,政府网站永远不可能屏蔽爬虫。而去爬二手数据来源,需要繁杂的反爬措施。
后端数据清洗方面,整个公司对于数据的治理还停留在线性叠加的水平上,而不是打造平台,从而能够横向拓展。比如说对于研报、新闻、招投标公告需要一套底层的文章库,而现在每一套的处理流程都是单独的,而且效率很低,没有人有整合的想法。相比之下,头条很早就有打造推荐引擎的想法。
抓取上,更是“脚本小子”的思路,每个项目都单独编写爬虫,主要精力竟然是放在了不同站点的反爬策略上,这一点是非常匪夷所思的。除了重点抓取的电商数据外,不应该有任何网站存在很复杂的反爬逻辑才对。另外就是单独编写的爬虫可维护性太差,其实就相当于内包给某个员工,业务的风险性太大。甚至经常出现某个人的脚本由于写得太差,把整个集群打挂的情形。
另一方面,对于客户预期管理可以说是很失败。从数据上说,我们不可能客户要什么数据就有什么数据,要说服客户使用我们的数据,尤其是抓不到的电商数据,完全可以通过统计学知识来得出结论。从系统上说,更不能为了一个客户去做定制开发,最终做成了一家高级外包公司。
项目管理
对于 Baelish 的搭建,我犯得一个错误就是问题考虑太复杂了。看了不少创业的书,心里很明白要先拿出一个 MVP 来,但是实际上却做不到,总是想着要做一个大而全的东西,过早优化太多了。 实际上开始就应该单机部署就行了,直接开一千个线程,然后就可以跑起来,这样的话,即使 20s 一个的请求,并发也可以在 50 了。
当然,这方面的另一个因素就是自己的技术知识当时实在还是匮乏,有些刚需的东西确实不懂,必须得学习一下,现在再来做这个东西的话就好多了。
总结
- 不要使用过于小众的基础组件,比如 celery、nomad。最好使用足够简单、且经过验证的系统, 比如 kubernetes,Kafka
- 要有自己的逻辑。科技公司还是要技术驱动,那些“非技术驱动论”的鼓吹者可以休矣!
参考


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站