$ ls ~yifei/notes/
SQLAlchemy 2.0 教程
Posted on:
Last modified:
SQLAlchemy 是 Python 生态系统中最流行的 ORM。SQLAlchemy 设计非常优雅,分为了两部分——底层的 Core 和上层的传统 ORM。在 Python 乃至其他语言的大多数 ORM 中,都没有实现很好的分层设计, 比如 django 的 ORM,数据库链接和 ORM 本身完全混在一起。
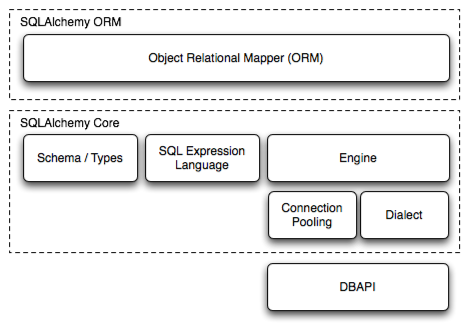
SQLAlchemy 当前版本是 1.4. 有两套 API,1.3 及之前的老 API 和 1.4 及之后的 2.0 兼容 API。 本文中只介绍 2.0 API。
为什么要有 Core
Core 层主要实现了客户端连接池。我们知道,作为现代 Web 应用的核心,关系型数据库的并发连接
能力往往并不是很强,一般不要搞好多短连接过去,大多数情况下需要一个连接池。连接池大体分为
两种,一种在服务端,也就是一个专门的连接池中间件,给短连接每次分配一个长链接复用。另一种
在客户端,一般作为第三方库引入代码中。SQLAlchemy 的连接池显然是客户端的。在这个连接池中,
SQLAlchemy 维护了一定数量的长连接,当调用 connect 时,实际是从池子中取出了一个链接,
调用 close 时,实际是放回到了池子中一个链接。
创建链接
SQLAlchemy 中使用 create_engine 来创建连接(池)。create_engine 的参数是数据库的 URL。
from sqlalchemy import create_engine
engine = create_engine(
"mysql://user:password@localhost:3306/dbname",
echo=True, # echo 设为 True 会打印出实际执行的 sql,调试的时候更方便
future=True, # 使用 SQLAlchemy 2.0 API,向后兼容
pool_size=5, # 连接池的大小默认为 5 个,设置为 0 时表示连接无限制
pool_recycle=3600, # 设置时间以限制数据库自动断开
)
# 创建一个 SQLite 的内存数据库,必须加上 check_same_thread=False,否则无法在多线程中使用
engine = create_engine("sqlite:///:memory:", echo=True, future=True,
connect_args={"check_same_thread": False})
# pip install mysqlclient
engine = create_engine('mysql+mysqldb://user:password@localhost/foo?charset=utf8mb4')Core 层 -- 直接使用 SQL
CRUD
from sqlachemy import text
with engine.connect() as conn:
result = conn.execute(text("select * from users"))
print(result.all())
# result 可以遍历,每一个行结果是一个 Row 对象
for row in result:
# row 对象三种访问方式都支持
print(row.x, row.y)
print(row[0], row[1])
print(row["x"], row["y"])
# 传递参数,使用 `:var` 传递
result = conn.execute(
text("SELECT x, y FROM some_table WHERE y > :y"),
{"y": 2}
)
# 也可以预先编译好参数
stmt = text("SELECT x, y FROM some_table WHERE y > :y ORDER BY x, y").bindparams(y=6)
# 插入时,可以直接插入多条
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 11, "y": 12}, {"x": 13, "y": 14}]
)事务与 commit
SQLAlchemy 提供两种提交的方式,一种是手工 commit,一种是半自动 commit。官方文档建议使用 engine.begin()。还有一种完全自动的,每一行提交一次的 autocommit 方式,不建议使用。
# "commit as you go" 需要手动 commit
with engine.connect() as conn:
conn.execute(text("CREATE TABLE some_table (x int, y int)"))
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 1, "y": 1}, {"x": 2, "y": 4}]
)
conn.commit() # 注意这里的 commit
# "begin once" 半自动 commit
with engine.begin() as conn:
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 6, "y": 8}, {"x": 9, "y": 10}]
)ORM
Session 不是线程安全的。但是一般情况下,web 框架应该在每个请求开始时获取一个 session, 所以也不是问题。
from sqlalchemy.orm import Session
with Session(engine) as session:
session.add(foo)
session.commit()
# 还可以使用 sessionmaker 来创建一个工厂函数,这样就不用每次都输入参数了
from sqlachemy.orm import sessionmaker
new_session = sessionmaker(engine)
with new_session() as session:
...声明式 API
- 使用
__tablename__指定数据库表名 - 使用 Mapped 和原生类型声明每个字段
- 使用 Integer/String... 指定字段类型
- 使用 index 参数指定索引
- 使用 unique 参数指定唯一索引
- 使用
__table_args__指定其他属性,比如联合索引
from datetime import datetime
from sqlalchemy import Integer, String, func, UniqueConstraint
from sqlalchemy.orm import relationship, mapped_column, Mapped
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "users"
# 必须是 tuple,不能是 list,闲得慌……
__table_args__ = (UniqueConstraint("name", "time_created"),)
id: Mapped[int] = mapped_column(Integer, primary_key=True)
name: Mapped[str] = mapped_column(String(30), index=True)
fullname: Mapped[str] = mapped_column(String, unique=True)
# 对于特别大的字段,还可以使用 deferred,这样默认不加载这个字段
description: Mapped[str] = mapped_column(Text, deferred=True)
# 默认值,注意传递的是函数,不是现在的时间
time_created: Mapped[datetime] = mapped_column(DateTime(Timezone=True), default=datetime.now)
# 或者使用服务器默认值,但是必须在表创建的时候就设置好,会成为表的 schema 的一部分
time_created: Mapped[datetime] = mapped_column(DateTime(timezone=True), server_default=func.now())
time_updated: Mapped[datetime] = mapped_column(DateTime(timezone=True), onupdate=func.now())
class Address(Base):
__tablename__ = "address"
id: Mapped[int] = mapped_column(Integer, primary_key=True)
email_address: Mapped[str] = mapped_column(String, nullable=False)
# 调用 create_all 创建所有模型
Base.metadata.create_all(engine)
# 如果只需要创建一个模型
User.__table__.create(engine)外键
使用 relationship 来制定模型之间的关联关系。
一对多关系的双向映射
from sqlalchemy import create_engine, Integer, String, ForeignKey
from sqlalchemy.orm import DeclarativeBase, relationship, Session, Mapped, mapped_column
class Group(Base):
__tablename__ = 'groups'
id: Mapped[int] = mapped_column(Integer, primary_key=True)
name: Mapped[str] = mapped_column(String)
# 对应的多个 users,这里使用模型名作为参数
members = relationship('User')
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
# group_id 是数据库中真实存在的外键名,第二个字段 ForeignKey 用来指定对应的 ID
group_id = Column(Integer, ForeignKey('groups.id'))
# 模型中对应的 group 字段,需要声明和对应模型中的哪个字段是重合的
group = relationship('Group', overlaps="members")多对多映射,需要使用一个关联表。
# 关联表
class UserPermissions(Base):
__tablename__ = 'user_permissions'
id: Mapped[int] = mapped_column(Integer, primary_key=True)
# 同样用 foreign key 指定外键
user_id: Mapped[int] = mapped_column(Integer, ForeignKey('users.id'))
permission_id: Mapped[str] = mapped_column(String, ForeignKey('permissions.id'))
class User(Base):
__tablename__ = 'users'
id: Mapped[int] = mapped_column(Integer, primary_key=True)
name: Mapped[str] = Column(String)
# 使用 secondary 指定关联表,同样用 overlaps 指定对应模型中的字段
permissions = relationship('Permission', secondary="user_permissions", overlaps="users")
class Permission(Base):
__tablename__ = 'permissions'
id: Mapped[int] = mapped_column(Integer, primary_key=True)
name: Mapped[str] = Column(String)
# 同上
users = relationship('User', secondary="user_permissions", overlaps="permissions")
user1 = User(name='user1', group_id=1)
user2 = User(name='user2')
group1 = Group(name='group1')
group2 = Group(name='group2', members=[user2])
permission1 = Permission(name="open_file")
permission2 = Permission(name="save_file")
user1.permissions.append(permission1)
db.add_all([user1, user2, group1, group2, permission1, permission2])
db.commit()
print(user1.permissions[0].id)其他的教程中大多使用 backref 来生成对应模型的属性,我并不喜欢这样,更倾向于在对应的模型中
都显式声明可以访问的属性。
CRUD
和 1.x API 不同,2.0 API 中不再使用 query,而是使用 select 来查询数据。网上的诸多教程还在 讲解 query API,最好不要参考这些教程了。
from sqlalchemy import select
# where 的参数是 `==` 构成的表达式,好处是写代码的时候,拼写错误就会被检查到
stmt = select(User).where(User.name == "john").order_by(User.id)
# filter_by 使用 **kwargs 作为参数
stmt = select(User).filter_by(name="some_user")
# order_by 还可以使用 User.id.desc() 表示逆序排列
result = session.execute(stmt)
# 一般情况下,当选取整个对象的时候,都要用 scalars 方法,否则返回的是一个包含一个对象的 tuple
for user in result.scalars():
print(user.name)
# 查询模型单个属性时,不需要使用 scalars
result = session.execute(select(User.name))
for row in result:
print(row.name)
# 按照 id 查询还有一个快捷方式:
user = session.get(User, pk=1)
# 更新数据需要使用 update 语句
from sqlalchemy import update
# synchronize_session 有三种选项: false, "fetch", "evaluate",默认是 evaluate
# false 表示完全不更新 Python 中的对象
# fetch 表示重新从数据库中加载一份对象
# evaluate 表示在更新数据库的同时,也尽量在 Python 中的对象上使用同样的操作
stmt = update(User).where(User.name == "john").values(name="John").execution_options(synchronize_session="fetch")
session.execute(stmt)
# 或者直接对属性赋值
user.name = "John"
session.commit()
# 这里有一个可能引入 race condition(竞态条件)的地方
# 错误!如果两个进程同时更新这个值,可能导致只更新了一个值。
# 两者都赋值为自身认为的正确值 2,实际正确值为 1 + 1 + 1 = 3
# 对应 SQL:Update users set visit_count = 2 where user.id = 1
user.visit_count += 1
# 正确做法:注意大写的 U,也就是使用了模型的属性,生成的 SQL 是在 SQL 服务端 +1
# 对应 SQL: Update users set visit_count = visit_count + 1 where user.id = 1
user.visit_count = User.visit_count + 1
# 添加对象直接使用 session.add 方法
session.add(user)
# 或者 add_all
session.add_all([user1, user2, group1])
# 如果要获取插入后的 ID,当然也可以 commit 之后再读
session.flush() # flush 并不是 commit,并没有提交事务,应该是可重复读,和数据库的隔离级别有关。
print(user.id)
# 删除使用 session.delete
session.delete(user)加载关联模型
如果我们在读取一个 N 个记录的列表之后,再去数据库中一一读取每个项目的具体值,就会产生 N+1 个 查询。这就是数据库中最常犯的错误:N+1 问题。
默认情况下,查询中不会加载外键关联的模型,可以使用 selectinload 选项来加载外键,从而避免
N+1 问题。select(Model).options(selectinload(Model.field))
- session.execute(select(User)).scalars().all() # 没有加载 parent 外键
+ session.execute(select(User).options(selectinload(User.groups))).scalars().all()Selectinload 的原理在于使用了 select in 子查询,这也是名字的又来。除了 selectinload 外,
还可以使用传统的 joinedload,它的原理就是最普通的 join table
# 使用 joinedload 加载外键,注意需要使用 unique 方法,这是 2.0 中规定的。
session.execute(select(User).options(joinedload(User.groups))).unique().scalars().all()在 2.0 中,更推荐使用 selectinload 而不是 joinedload,一般情况下,selectinload 都要好, 而且不用使用 unique.
外键的写入
SQLAlchemy 中,直接像处理数组一样处理外键就好了,这点非常方便。
user.permissions.append(open_permission) # 添加
user.permissions.remove(save_permission) # 删除
# 清空所有外键
user.permissions.clear()
user.permissions = []JSON 字段的特殊处理
大多数的数据库现在都支持 JSON 字段了,在 SQLAlchemy 中我们也可以直接从字段读取 json 对象 或者写入 json 对象。但是,千万不要直接对这个 json 对象做 update 并期望写回数据库中,这是 不可靠的。一定要复制后读写,然后再赋值回去。
article = session.get(Article, 1)
tags = copy.copy(article.tags)
tags.append("iOS")
article.tags = tags
session.commit()批量插入
当需要插入大量数据的时候,如果依然采用逐个插入的方法,那么就会在和数据库的交互上浪费很多
时间,效率很低。MySQL 等大多数数据库都提供了 insert ... values (...), (...) ... 这种
批量插入的 API,在 SQLAlchemy 中也可以很好地利用这一点。
# 使用 session.bulk_save_objects(...) 直接插入多个对象
s = Session()
objects = [
User(name="u1"),
User(name="u2"),
User(name="u3")
]
s.bulk_save_objects(objects)
s.commit()
# 使用 bulk_insert_mappings 可以省去创建对象的开销,直接插入字典
users = [
{"name": "u1"},
{"name": "u2"},
{"name": "u3"},
]
s.bulk_insert_mappings(User, users)
s.commit()
# 使用 bulk_update_mappings 可以批量更新对象,字典中的 id 会被用作 where 条件,
# 其他字段全部用于更新
session.bulk_update_mappings(User, users)从 1.X API 迁移到 2.0 API
query -> execute
- session.query(User).get(42)
+ session.get(User, 42)
- session.query(User).all()
+ session.execute(select(User)).scalars().all()
- session.query(User).filter_by(name="some_user").one()
+ session.execute(select(User).filter_by(name="some_user")).scalar_one()
- session.query(User).from_statememt(text("select * from users")).a..()
+ session.execute(select(User).from_statement(text("selct * from users"))).scalars().all()
- session.query(User).filter(User.name == "foo").update({"fullname": "FooBar"}, synchronize_session="evaluate")
+ session.execute(update(User).where(User.name == "foo").values(fullname="FooBar").execute_options(synchronize_session="evaluate"))DeclarativeBase
全面拥抱 Python 原生类型系统
- from sqlalchemy.orm import declarative_base
+ from sqlalchemy.orm import DeclarativeBase
- Base = declarative_base()
+ class Base(DeclarativeBase):
+ pass
- from sqlalchemy import Column
+ from sqlalchemy.orm import mapped_column, MappedColumn
- id = Column(Integer, primary_key=True)
+ id: Mapped[int] = mapped_column(Integer, primary_key=True)
- fullname = Column(String)
+ fullname: Mapped[Optional[str]]Asyncio
One AsyncSession per task.
The AsyncSession object is a mutable, stateful object which represents a single, stateful database transaction in progress. Using concurrent tasks with asyncio, with APIs such as asyncio.gather() for example, should use a separate AsyncSession per individual task.
from sqlalchemy.ext.asyncio import create_async_engine, async_sessionmaker, AsyncSession
engine = create_async_engine(url, echo=True)
session = async_sessionmaker(engine)
# Creating objects
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.create_all)
# inserting
async with session() as db:
db.add(...)
await db.commit()
# selecting
async with session() as db:
stmt = select(A)
row = await db.execute(stmt)
for obj in rows.scalars():
print(obj.id)
await engine.dispose()sqlite
需要使用异步的 sqlite 驱动,比如 aiosqlite
pip install aiosqlite
engine = create_async_engine('sqlite+aiosqlite:///./database.db')imports
SQLAlchemy 的导出类型主要分布在以下三个部分:
# SQL 相关的直接从根目录导入,注意 Column 和 Integer 也在这里
from sqlalchemy import text, insert, select, create_engine, Integer, String
# ORM 相关的从 orm 子包中导入
from sqlalchemy.orm import DeclarativeBase, Session, sessionmaker, MappedColumn, mapped_column
# 异常从 exc 中导入
from sqlalchemy.exc import IntegrityError, SQLAlchemyError反射——从数据库创建模型
TODO
在 FastAPI 中使用
TODO
多进程环境下的使用
由于 Python 中 GIL 的原因,要利用多核处理器需要使用多进程。而多进程中,资源并不能共享, 对应到 SQLAlchemy,也就是连接池不能共享。
我们需要手工解决这个问题。
一般情况下,最好不要尝试在多个进程中共享同一个 Session。最好在每个进程初始化时创建 Session。
仅在设定值时增加 where 条件
在 URL 中,经常需要根据用户指定了哪些选项来返回对应的结果。
query = select(User)
if username is not None:
query = query.where(User.username == username)
if password is not None:
query = query.where(User.password == password)参考
- https://docs.sqlalchemy.org/en/14/tutorial/orm_related_objects.html
- https://stackoverflow.com/questions/25668092/flask-sqlalchemy-many-to-many-insert-data
- https://stackoverflow.com/questions/9667138/how-to-update-sqlalchemy-row-entry
- https://docs.sqlalchemy.org/en/14/changelog/migration_20.html
- https://stackoverflow.com/questions/13370317/sqlalchemy-default-datetime
- https://amercader.net/blog/beware-of-json-fields-in-sqlalchemy/
- https://stackoverflow.com/questions/26948397/how-to-delete-records-from-many-to-many-secondary-table-in-sqlalchemy
- Count by many to many foreign key
- https://stackoverflow.com/questions/19175311/how-to-create-only-one-table-with-sqlalchemy/19175907
- https://stackoverflow.com/questions/63220132/sqlalchemy-insert-to-mysql-db-unicodeencodeerror-for-cyrlic-data
- https://stackoverflow.com/questions/41279157/connection-problems-with-sqlalchemy-and-multiple-processes
- https://docs.sqlalchemy.org/en/14/core/pooling.html
- https://stackoverflow.com/questions/10059345/sqlalchemy-unique-across-multiple-columns
- https://stackoverflow.com/questions/22876946/how-to-order-by-count-of-many-to-many-relationship-in-sqlalchemy
- https://docs.sqlalchemy.org/en/20/changelog/whatsnew_20.html
- https://stackoverflow.com/questions/66431083/using-asyncio-extension-with-sqlite-backend-broken-by-version-upgrade


© 2016-2022 Yifei Kong. Powered by ynotes
All contents are under the CC-BY-NC-SA license, if not otherwise specified.
Opinions expressed here are solely my own and do not express the views or opinions of my employer.
友情链接: MySQL 教程站